June 9, 2026
Cohere just released North Mini Code, a small 30B parameter (3B active) open weights coding model that scores 27.6 on the Artificial Analysis Intelligence Index
Less than a month since Cohere‘s last model release, Command A+, has launched another open weights model that is optimized for coding, and much smaller at 30B total parameters and 3B active parameters.
Key Takeaways:
➤ Achieves 27.6 on the Artificial Analysis Intelligence Index, above gpt-oss-20B (high) at 24.5 and just below Mistral Small 4 (119B parameters, 6.5B active) at 27.8
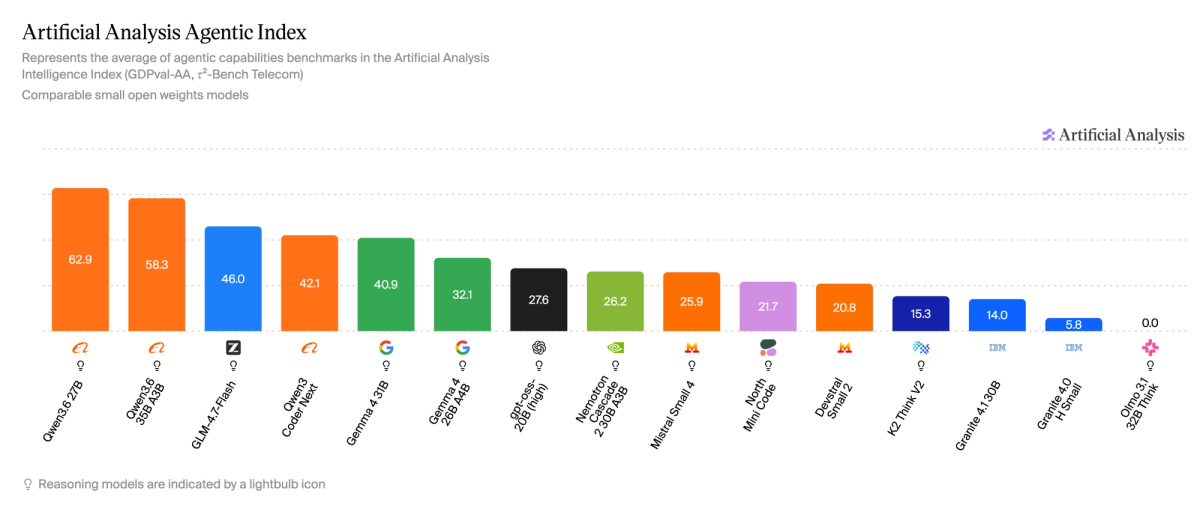
➤ Scores competitively on the Artificial Analysis Coding Index (weighted average of Terminal-Bench Hard and SciCode) against open weights models in its size class, scoring 33.4, significantly above GLM-4.7-Flash at 25.9, and below Qwen3.6 35B A3B at 35.2. However, it underperforms on non-coding agentic tasks, scoring 14% on GDPval-AA and 37% on 𝜏²-Bench Telecom
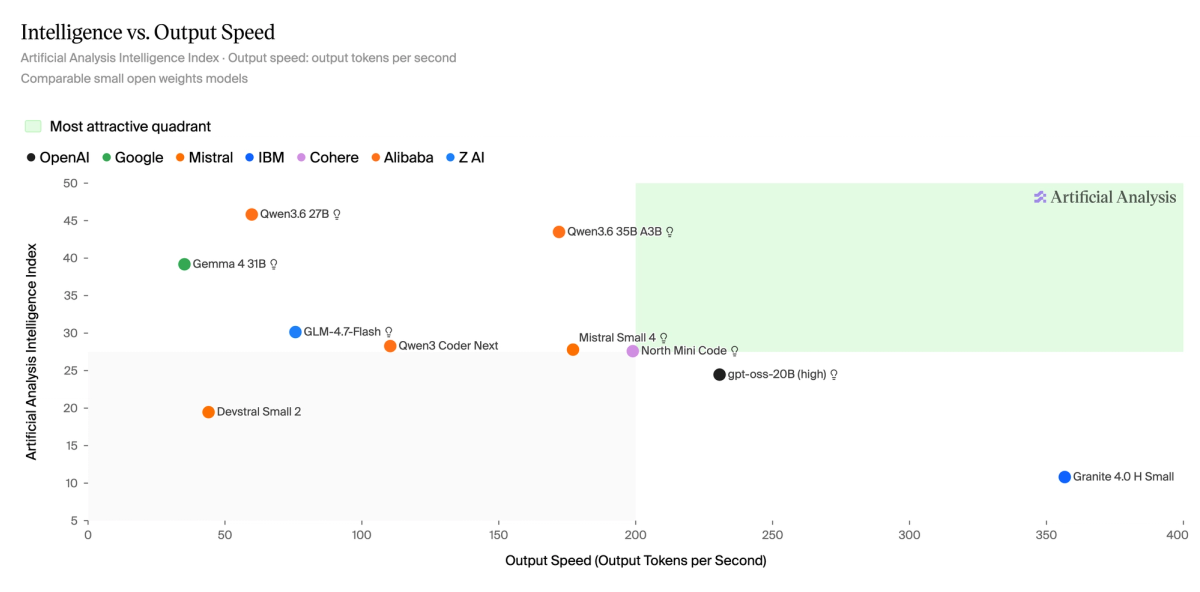
➤ On Cohere’s API, North Mini Code is faster than several comparable open weights models of its intelligence and size class (~199 output tokens per second)
➤ North Mini Code is a text-only 30B total parameter and 3B active parameter model, and is open-sourced under the Apache 2.0 license
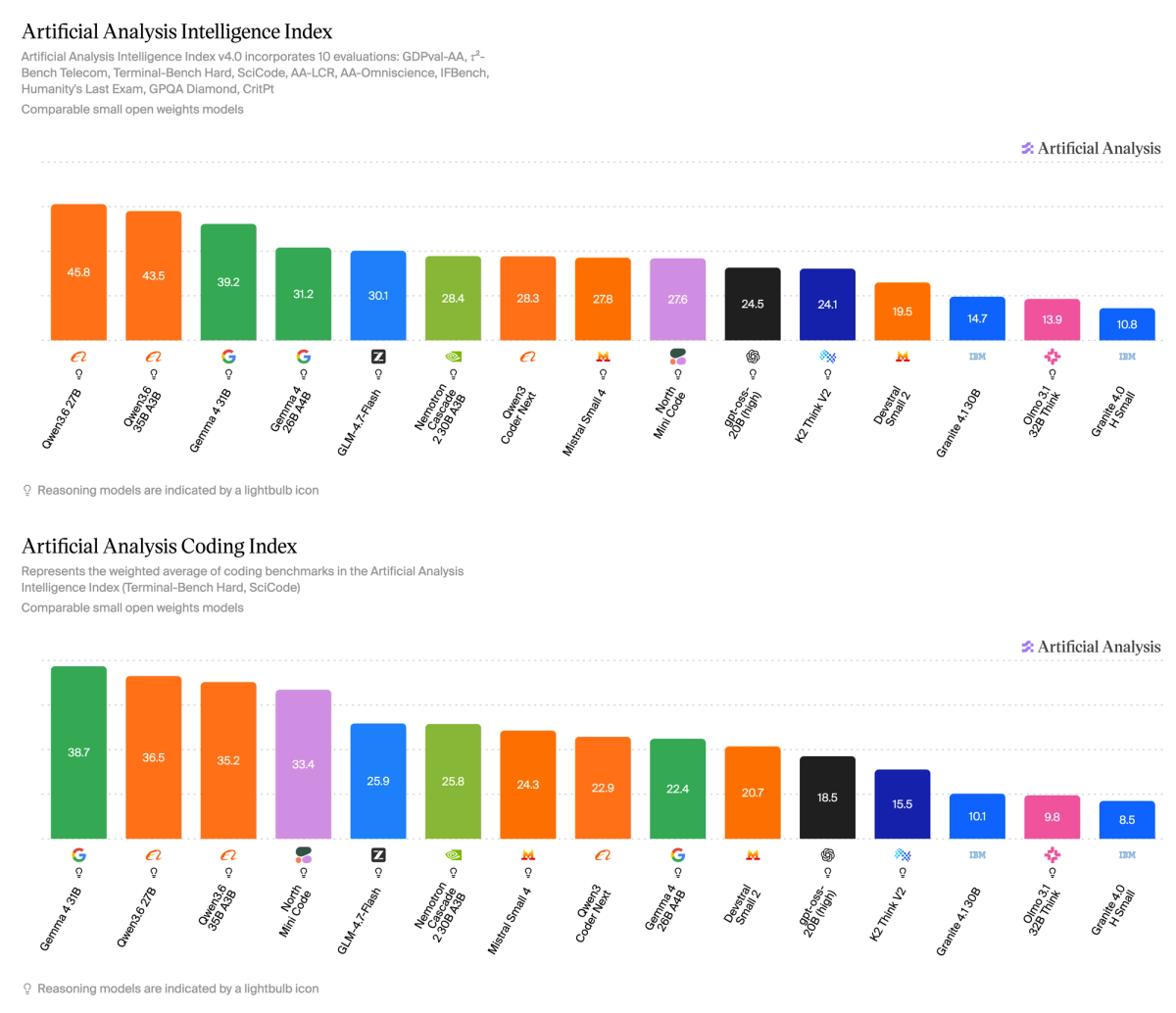
North Mini Code scores 14% on GDPval-AA and 37% on 𝜏²-Bench Telecom, resulting in an overall weighted score of 21.7 on the Artificial Analysis Agentic Index
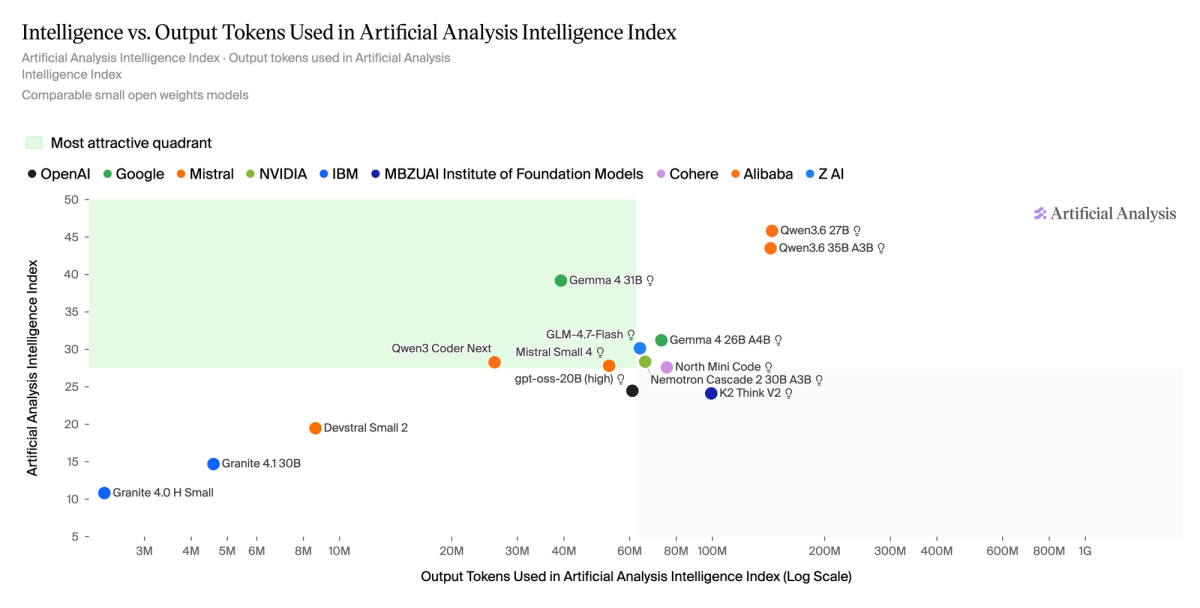
North Mini Code uses more output tokens to complete the Artificial Analysis Intelligence Index evaluations suite than most comparable models of its size and intelligence
In our pre-release speed testing, North Mini Code performed above several comparable open weights models of its intelligence and size class (~199 output tokens per second)
Full intelligence evaluations breakdown below:
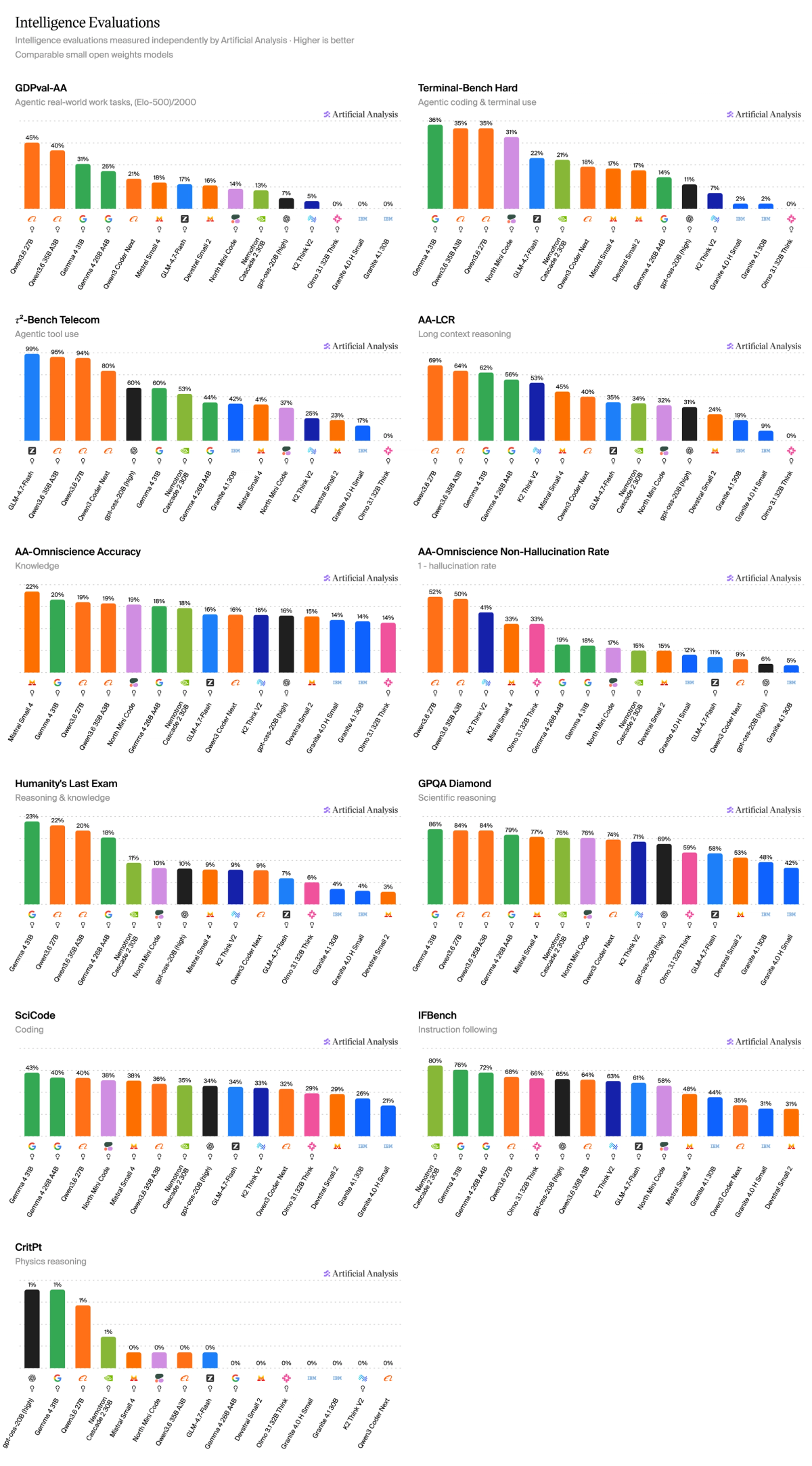
See Artificial Analysis for further details and benchmarks: https://artificialanalysis.ai/models/north-mini-code
Read the latest

Four frontier launches in eight days: six labs now field a model above 50 on the Artificial Analysis Intelligence Index
Yeah. Grok 4.5, GPT-5.6, Muse Spark 1.1, and Kimi K3 all launched within eight days. Six labs now have a model scoring above 50 on the Artificial Analysis Intelligence Index, up from two in early June - and the price of near-frontier intelligence has collapsed
July 17, 2026

Kimi K3 achieves #3 in the Artificial Analysis Intelligence Index, comparable to Opus 4.8 and GPT-5.5
Benchmarks and Analysis of Kimi K3
July 17, 2026

Thinking Machines has released Inkling, the new leading U.S. open weights model
Thinking Machines has released Inkling, the new leading U.S. open weights model, debuting at 41 on the Artificial Analysis Intelligence Index
July 15, 2026