June 1, 2026
Announcing AA-WER Streaming, our new benchmark measuring streaming Speech to Text models on accuracy and latency for voice agent use cases. Pareto optimal models on this new benchmark include those from Cartesia, ElevenLabs, and Deepgram
Streaming Speech to Text (STT) powers real-time transcription in voice agents and live captioning, where models must balance accuracy against speed. Fast transcripts are especially important for keeping responses feeling natural and leaves more of the response-time budget for reasoning and tool calls. Accuracy also matters since transcription errors compound in downstream reasoning and speech generation.
Streaming STT models transcribe audio as it is fed in, sharing outputs continuously, unlike offline (batch) models that process the entire file at once and are typically slower.
What we measure:
AA-WER Streaming reports Word Error Rate and latency together, measured from the moment end of speech is detected, with a Pareto line of increasing accuracy as time to transcript received increases. For direct comparability to offline models on accuracy, we test these streaming models on the same ~8 hours of audio as our offline benchmark, AA-WER v2.0: AA-AgentTalk, Earnings22-Cleaned-AA, VoxPopuli-Cleaned-AA.
We measure WER and latency as paired metrics at two points after Silero VAD-detected end of speech:
First Final Transcription: WER is measured on the first final-denoted transcript returned after end of speech is detected. Latency is the time in seconds from end of speech to that final-denoted transcript. This is more useful for understanding performance as a standalone streaming transcription model, and for higher accuracy.
First Partial Transcription: WER is measured on the first transcript-bearing event (partial or final) returned after end of speech is detected. Latency is the time in seconds from end of speech to that first transcript event. This is more useful for near instantaneous transcription for lower-accuracy tasks like responding to "yes" or "no" questions, or for speculative decoding.
Key results:
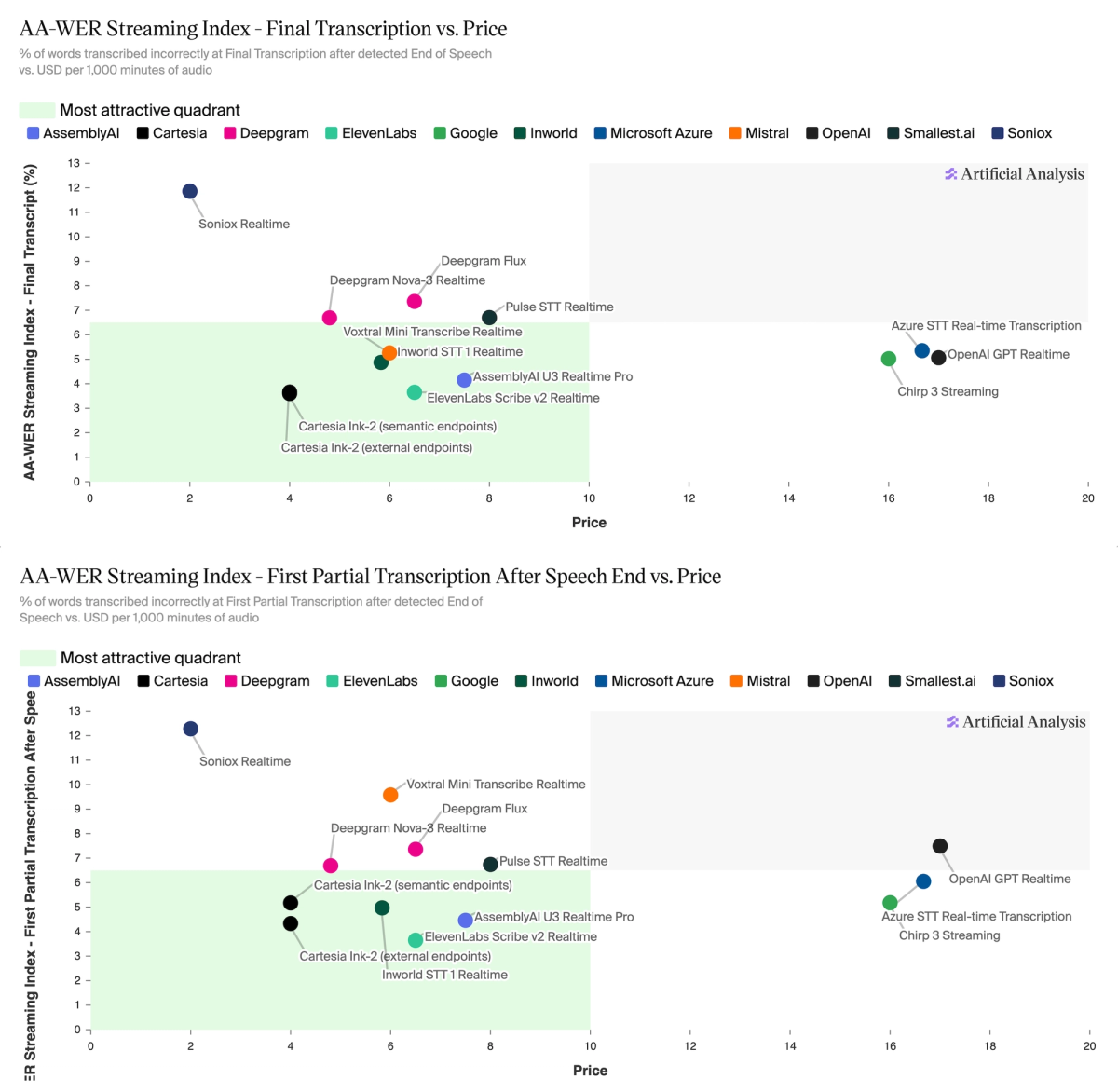
➤ Highest accuracy on Final after End of Speech: @Cartesia Ink-2 (semantic endpoints) at 3.59% WER, 0.21s latency, followed by ElevenLabs Scribe v2 Realtime (3.64%, 0.14s) and Cartesia Ink-2 (external endpoints) (3.66%, 0.09s)
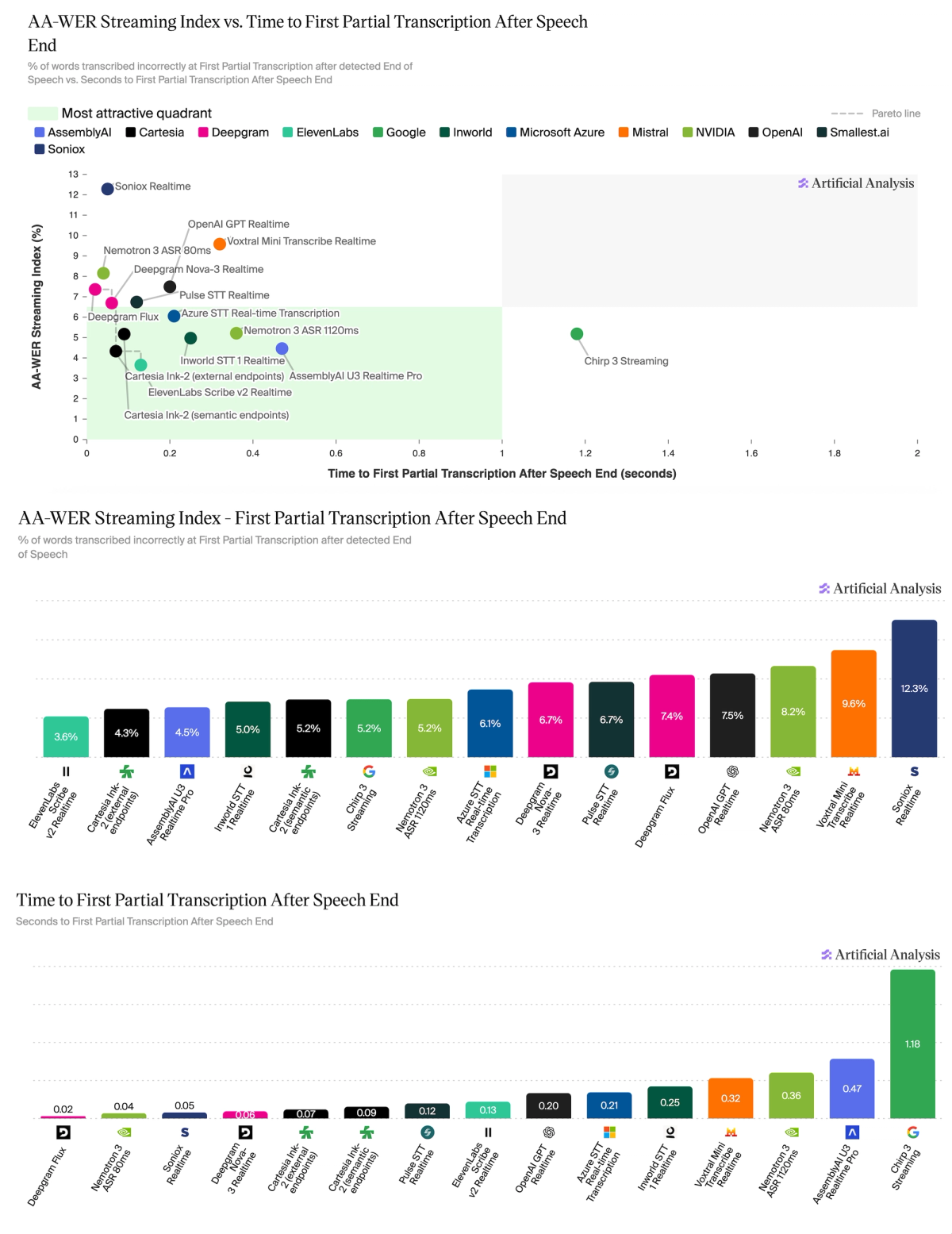
➤ Highest accuracy on First Partial after End of Speech: @ElevenLabs Scribe v2 Realtime at 3.65% WER, 0.13s latency, followed by Cartesia Ink-2 (external endpoints) (4.33%, 0.07s) and @AssemblyAI U3 Realtime Pro (4.46%, 0.47s)
➤ Fastest transcription: @DeepgramAI Flux leads both Final and Partial at 0.020s and 0.019s respectively (both 7.36% WER). On Final, it's followed by @soniox_ai Realtime and Deepgram Nova-3 Realtime (both 0.06s); on First Partial, it’s followed by @NVIDIA Nemotron 3 ASR 80ms (0.04s) and Soniox Realtime (0.05s)
Charts below include a Pareto frontier of accuracy vs. speed, so you can shortlist the models that best fit your latency constraints while still achieving high accuracy. See below for further detail ⬇️
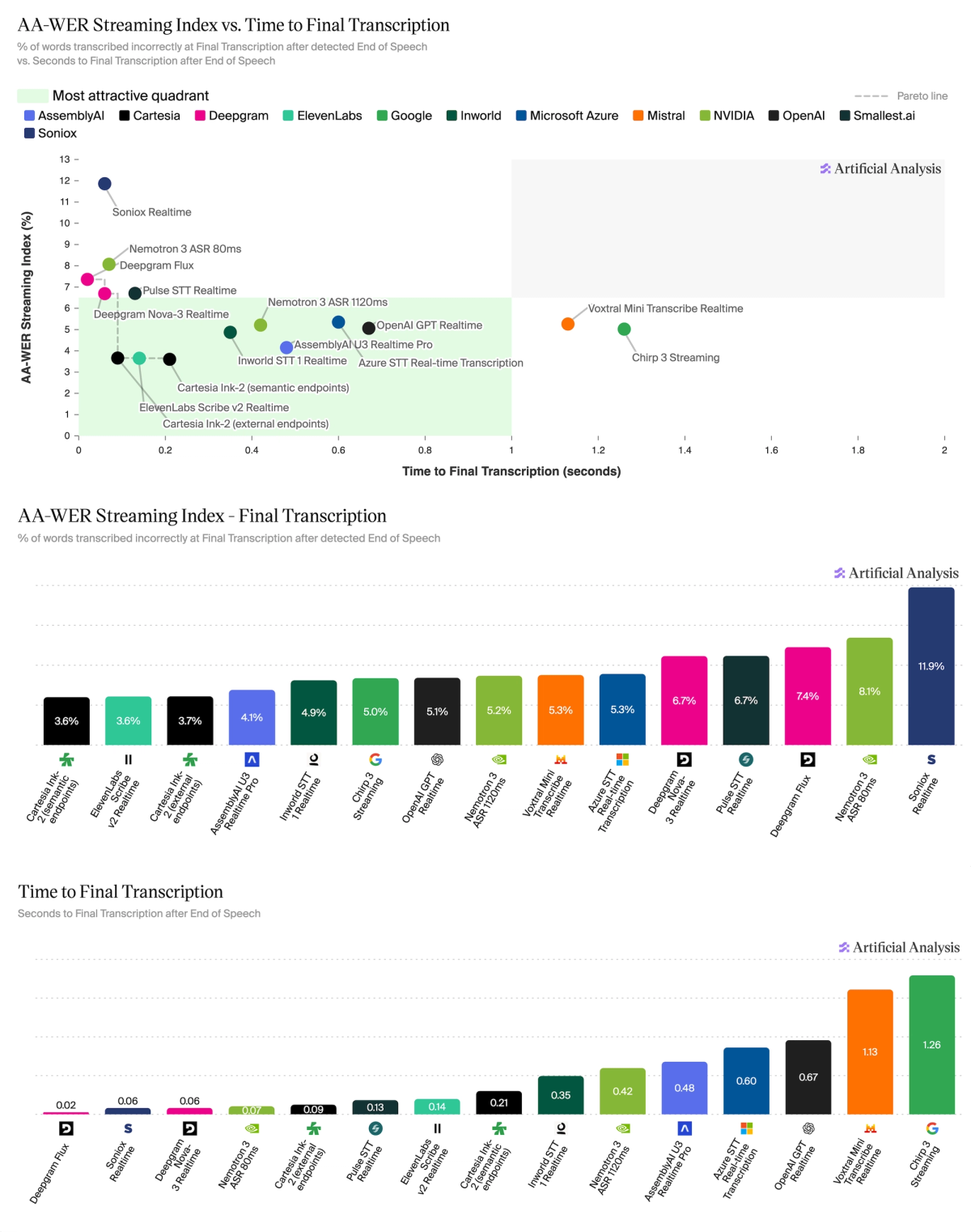
On the first partial frontier are Deepgram Flux (7.36%, 0.019s), Deepgram Nova-3 Realtime (6.69%, 0.057s), Cartesia Ink-2 (external endpoints) (4.33%, 0.072s), and ElevenLabs Scribe v2 Realtime (3.65%, 0.132s).
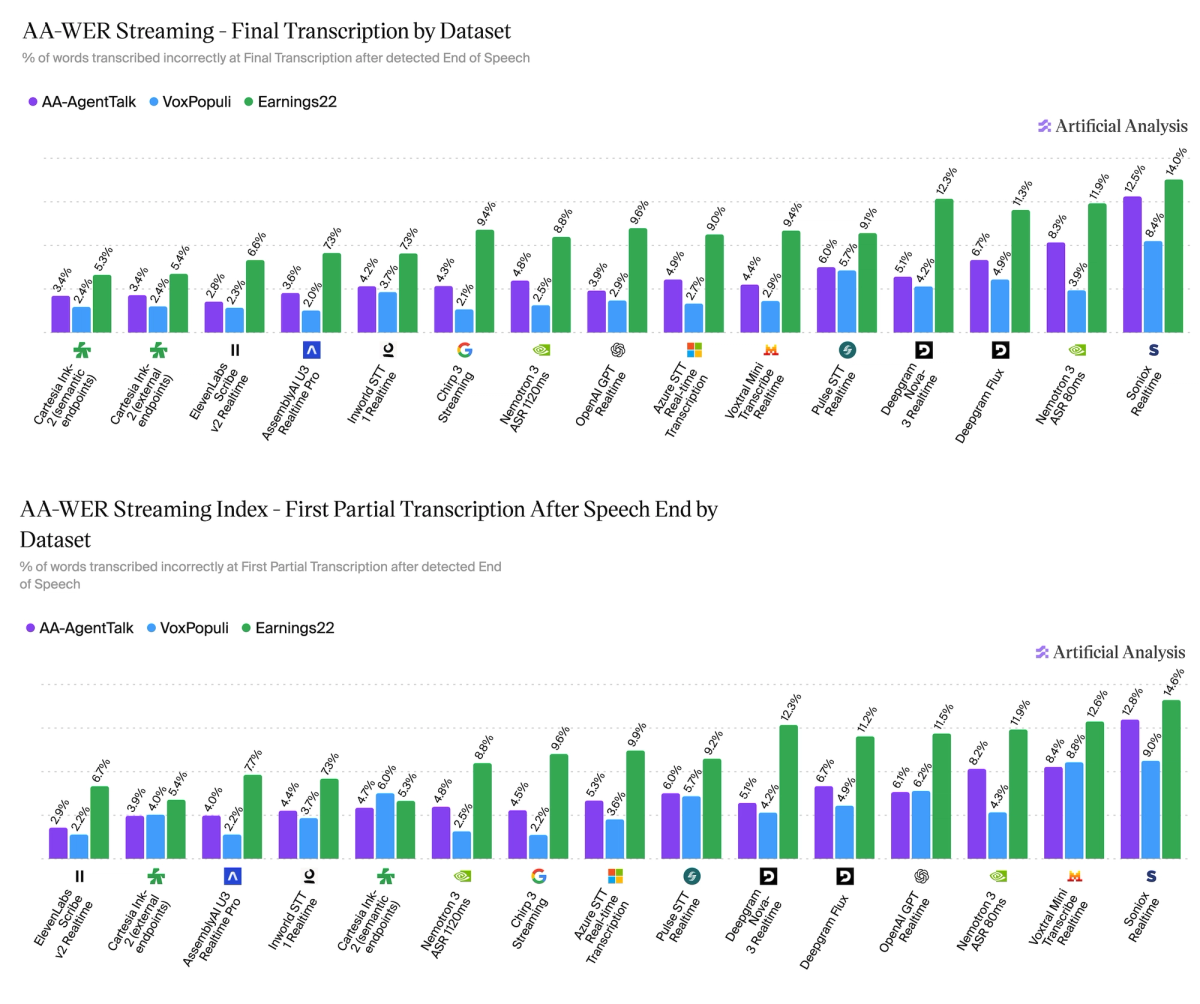
Performance varies meaningfully across the three datasets with different audio lengths, accents, vocabulary, and background noise. On AA-AgentTalk, our private test set, ElevenLabs Scribe v2 Realtime leads both final (2.8%) and partial (2.9%); on VoxPopuli, AssemblyAI U3 Realtime Pro leads final at 2.0% and Google’s Chirp 3 Streaming leads partial at 2.2%; on Earnings22, Cartesia Ink-2 (semantic endpoints) leads both at 5.3%. No single model leads everywhere.
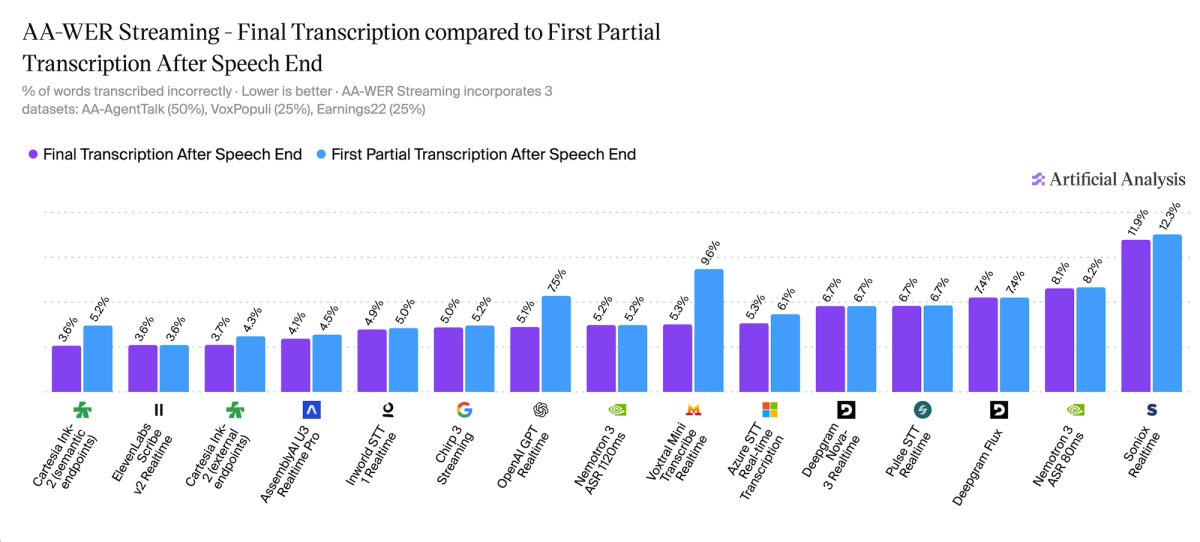
Across the streaming STT models tested, Final transcription is only ~0.7pp more accurate than First Partial on average. Most models are already at their final accuracy by the first partial (e.g., ElevenLabs Scribe v2 Realtime 3.6% WER at both, Deepgram Nova-3 6.7% at both, Deepgram Flux 7.4% at both). A handful improve materially by waiting for the final, led by Voxtral Mini Transcribe Realtime (9.6%→5.3%) and OpenAI GPT Realtime Whisper (7.5%→5.1%).
Streaming STT pricing spans $2 to $17 per 1k minutes. Cartesia Ink-2 (external endpoints) ($4, 3.7% WER) and ElevenLabs Scribe v2 Realtime ($6.50, 3.6% WER, 0.14s) lead on price-final accuracy trade-off; Soniox is cheapest at $2, but least accurate at 11.9% WER.
Full results: https://artificialanalysis.ai/speech-to-text/streaming
Methodology: https://artificialanalysis.ai/speech-to-text/methodology
We’re hiring! https://artificialanalysis.ai/careers
Read the latest

DeepSeek V4 Flash 0731 scores 50 on the Artificial Analysis Intelligence Index, 10 points above previous DeepSeek V4 Flash
DeepSeek releases DeepSeek V4 Flash 0731
July 31, 2026

Inkling Small lands within a point of Inkling on the Artificial Analysis Intelligence Index with less than a third of the parameters
Thinking Machines' new Inkling Small scores 40 on the Artificial Analysis Intelligence Index, within a point of its flagship sibling Inkling with less than a third of the total and active parameters
July 30, 2026

Agnes AI releases Agnes 2.5 Pro Alpha
Agnes 2.5 Pro Alpha
July 29, 2026