June 9, 2026
Claude Fable 5: the first public Mythos-class model
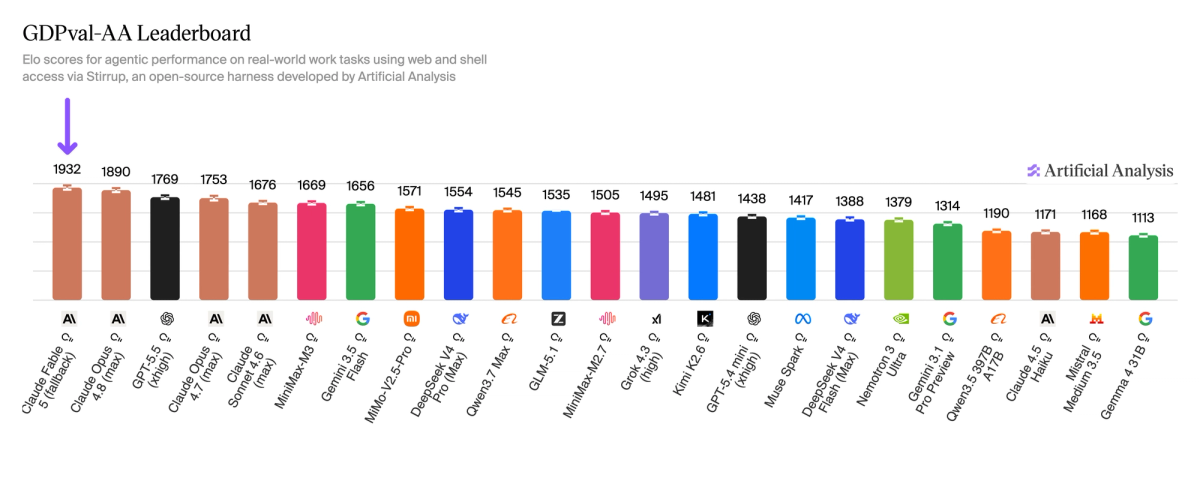
Anthropic has released Claude Fable 5, the first publicly available Mythos-class model that ranks #1 in our agentic real-world knowledge work benchmark GDPval-AA
Claude Fable 5 shares the same underlying model as Claude Mythos 5, with added security guardrails for potentially harmful cybersecurity, biology, chemistry, and distillation-related queries. The release also introduces a fallback mechanism, allowing Claude Fable 5 to route flagged queries to a second model such as Claude Opus 4.8.
Anthropic shared access with us ahead of public release to benchmark this model. Claude Fable 5 scores 1932 on GDPval-AA, our benchmark for agentic real-world work tasks, taking the #1 position and putting Anthropic models in 3 of the top 4 spots. The result was measured using adaptive reasoning at max effort, with Claude Opus 4.8 configured as the fallback model. Fable 5 falls back to Opus 4.8 on 2% of GDPval-AA tasks, with Anthropic stating that fallback occurs in fewer than 5% of sessions on average.
Read the latest

Four frontier launches in eight days: six labs now field a model above 50 on the Artificial Analysis Intelligence Index
Yeah. Grok 4.5, GPT-5.6, Muse Spark 1.1, and Kimi K3 all launched within eight days. Six labs now have a model scoring above 50 on the Artificial Analysis Intelligence Index, up from two in early June - and the price of near-frontier intelligence has collapsed
July 17, 2026

Kimi K3 achieves #3 in the Artificial Analysis Intelligence Index, comparable to Opus 4.8 and GPT-5.5
Benchmarks and Analysis of Kimi K3
July 17, 2026

Thinking Machines has released Inkling, the new leading U.S. open weights model
Thinking Machines has released Inkling, the new leading U.S. open weights model, debuting at 41 on the Artificial Analysis Intelligence Index
July 15, 2026