April 13, 2026
Sub-32B open weights models now offer GPT-5 level intelligence
Sub-32B open weights models now offer GPT-5 level intelligence with Qwen3.5 27B (Reasoning) matching GPT-5 (medium) at 42 and Gemma 4 31B (Reasoning) matching GPT-5 (low) at 39 on the Artificial Analysis Intelligence Index
Alibaba's Qwen3.5 and Google DeepMind's Gemma 4 are the two recently released open weights families pushing the sub-32B total parameter model class forward. Both are available across multiple sizes with reasoning and non-reasoning variants and offer native multimodal input. Together, they represent the state of the art in open weights intelligence at this parameter count. Qwen3.5 27B reaches higher absolute intelligence on the Artificial Analysis Intelligence Index, while Gemma 4 31B is more token-efficient.
While these sub-32B models now match GPT-5 tier intelligence, the composition of that intelligence differs. Both open weights models trail significantly on factual knowledge and hallucination avoidance compared to GPT-5 variants: AA-Omniscience scores of -42 (Qwen3.5 27B) and -45 (Gemma 4 31B) vs. -10 for GPT-5 (medium) and -10 for GPT-5 (low). Where the open weights models have made progress is largely in agentic performance and critical reasoning: Qwen3.5 27B substantially outperforms GPT-5 (medium) on the Artificial Analysis Agentic Index of 55 vs. 46 and Gemma 4 31B leads GPT-5 (low) on TerminalBench Hard (36% vs. 27%) and HLE (23% vs. 18%).
Both Qwen3.5 27B and Gemma 4 31B fit on a single NVIDIA H100 (80GB) in BF16 precision, and with quantization, can run locally on a MacBook. This is a practical threshold that makes these models accessible beyond the data centre. This is a significant shift from the previous generation: Gemma 3 was released in March 2025 as a non-reasoning model and scored 10 on the Intelligence Index. Qwen3 had two iterations - the original Qwen3 family and the 2507 update, with the flagship Qwen3 235B A22B (Reasoning) scoring 20 on the original and 30 on the 2507 variant.
Key takeaways:
➤ Qwen3.5 27B (Reasoning) scores 42 on the Intelligence Index using 98M output tokens, while Gemma 4 31B (Reasoning) scores 39 using 39M. This 2.5x token efficiency gap is the key tradeoff. Qwen3.5 27B's strength is broad - GPQA (86%) and IFBench (76%) - while Gemma 4 31B leads on SciCode (+3.9 p.p.) and TerminalBench Hard (+3.8 p.p.).
➤ Both families ship native multimodal input across the sub-32B class. Qwen3.5 27B (Reasoning) scores 75% on MMMU-Pro and Gemma 4 31B (Reasoning) scores 73%, making them the two leading open weights options at this parameter count for applications requiring vision understanding.
➤ Despite matching GPT-5 score tiers, both models trail by a wide margin on AA-Omniscience - a known correlation with smaller model size: Qwen3.5 27B (Reasoning) scores -42 and Gemma 4 31B (Reasoning) scores -45. By comparison, GPT-5 (medium) scores -10, and Qwen3.5's own 397B A17B sibling scores -30. Knowledge recall benefits from larger parameter counts, and these sub-32B models cannot close that gap with reasoning effort alone.
➤ The open weights frontier has also advanced significantly beyond 32B parameter size. GLM-5.1 (Reasoning) leads open weights on the Intelligence Index at a score of 51, Kimi K2.5 (Reasoning) at 47, and Qwen3.5 397B A17B (Reasoning) at 45, although these models are much larger than the sub-32B models. The gap between top open weights models and the proprietary frontier (Gemini 3.1 Pro Preview and GPT-5.4 (xhigh) at 57) has narrowed to just 6 points.
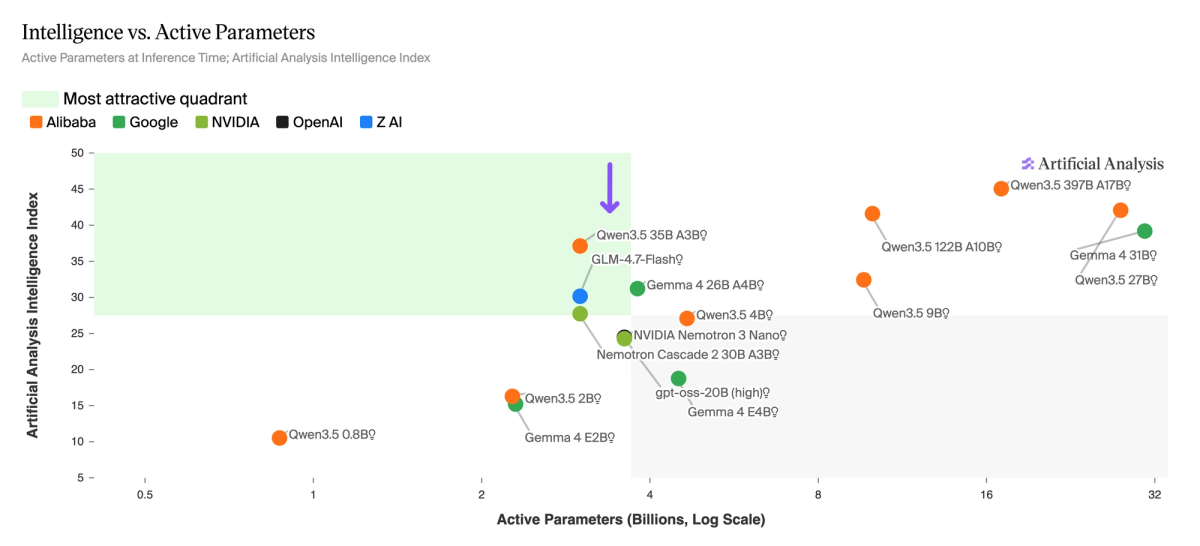
➤ Qwen3.5 occupies the Pareto frontier for Intelligence vs. Total Parameters and Intelligence vs. Active Parameters among open weights models under 32B. The dense 27B (Reasoning) at 42 matches the 122B A10B MoE at one-fifth the total weight, and the 35B A3B (Reasoning) scores 37 while activating just 3B parameters. Gemma 4 31B (Reasoning) at 39 is the main challenger on total parameters, and the 26B A4B (Reasoning) at 31 competes at the ~4B active tier.
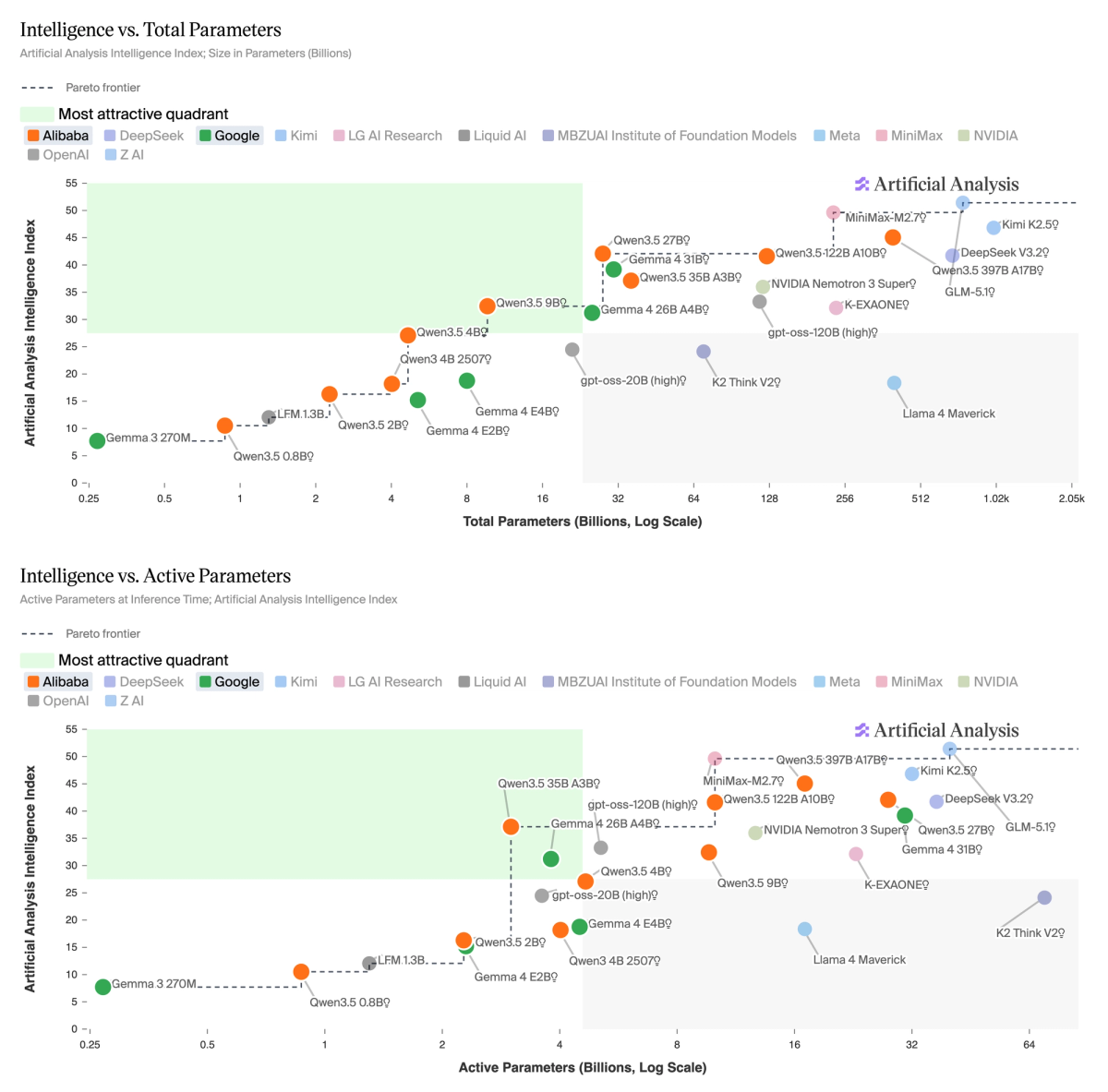
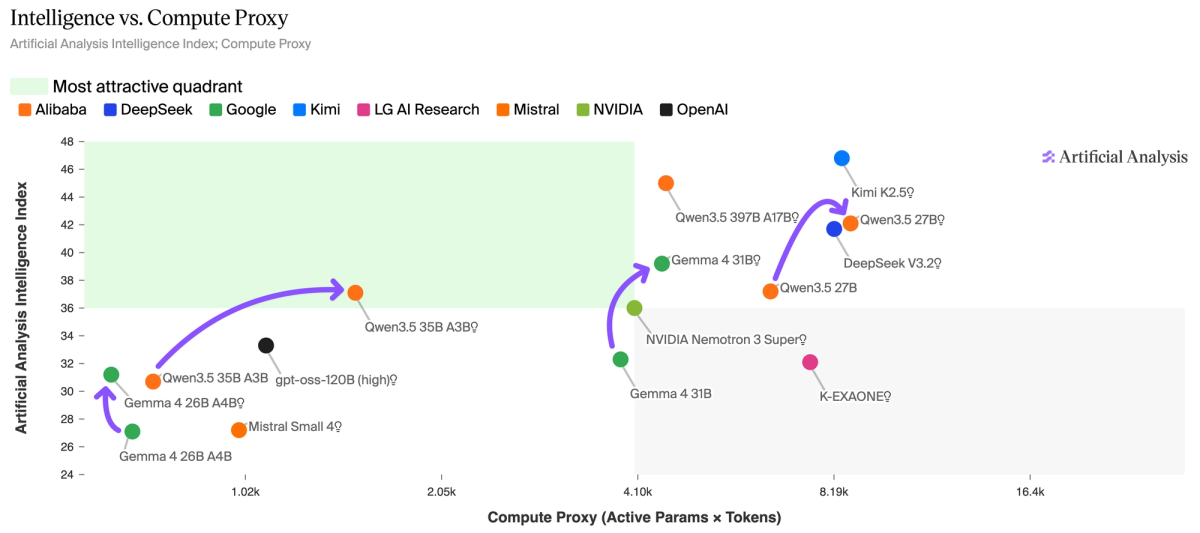
Gemma 4 is on the Pareto frontier of Intelligence vs. Compute Proxy - a metric we developed to estimate total inference compute, accounting for both active parameters and token generation. Qwen3.5 35B A3B (Reasoning) scores 37 but consumes 100M output tokens, while Gemma 4 26B A4B (Reasoning) scores 31 on just 73M tokens.
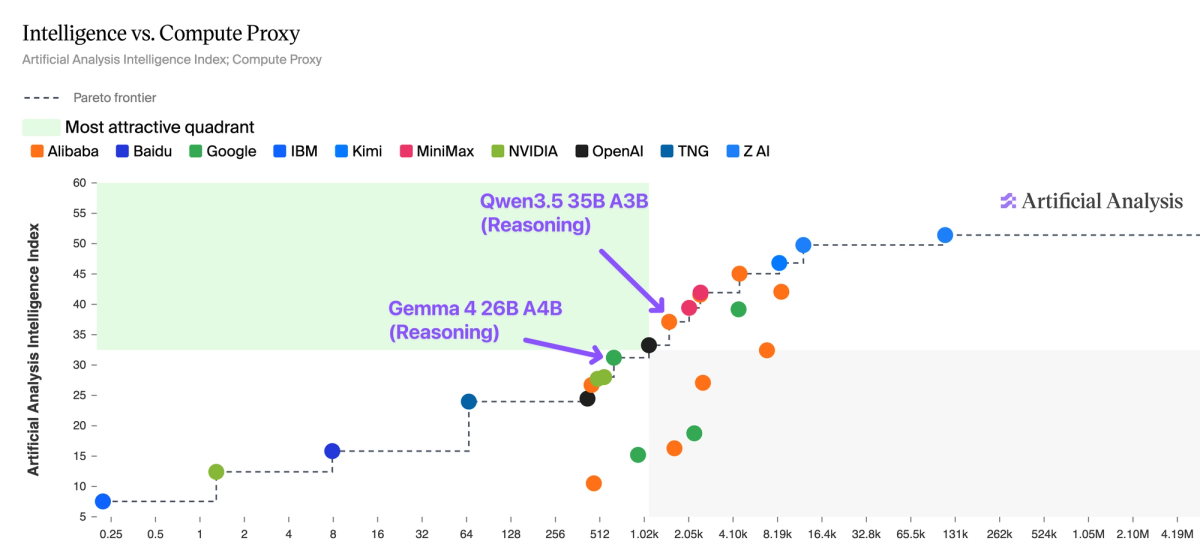
The ~3-4B active parameter tier is increasingly competitive - it now has six models competing from five different labs. A year ago, this tier did not exist. Qwen3.5 35B A3B (Reasoning) leads on the Intelligence Index at 37, followed by Gemma 4 26B A4B (Reasoning) at 31, GLM-4.7-Flash (Reasoning) at 30, Nemotron Cascade 2 30B A3B at 28, and gpt-oss-20B (high) and NVIDIA Nemotron 3 Nano 30B A3B (Reasoning) both at ~24. The rapid convergence of multiple labs on the ~3-4B active parameter point reflects a broader shift toward MoE architectures optimized for inference cost at the edge and smaller, more intelligent dense models overall.
Non-reasoning modes are competitive in the sub-32B open weights field. Gemma 4 31B (Non-reasoning) scores 32 on the Intelligence Index using just 7.1M output tokens - 5.5x fewer than its reasoning mode for only a 7-point decrease. Qwen3.5 27B (Non-reasoning) scores 37 using 25M tokens - 4x fewer than its reasoning mode for a 5-point decrease. For latency-sensitive or high-throughput deployments, these non-reasoning modes now match where frontier reasoning models scored less than a year ago, at a fraction of the compute.
Read the latest

How Thinking Machines Lab’s Inkling performs on agentic knowledge work
Thinking Machines Lab’s Inkling scores an Elo of 836 on on our agentic knowledge work benchmark AA-Briefcase
July 22, 2026

Kimi K3: second only to Fable 5 on AA-Briefcase
Kimi K3 is second only to Fable 5 on AA-Briefcase, our agentic knowledge work benchmark, but costs more than Opus 4.8 to run while averaging nearly an hour per task
July 21, 2026

Gemini 3.6 Flash and Gemini 3.5 Flash-Lite: Halving Time per Task
Google has released Gemini 3.6 Flash and Gemini 3.5 Flash-Lite. Both halve time per task relative to their predecessors and increase token efficiency, Gemini 3.5 Flash-Lite improves by 11 Intelligence Index points while Gemini 3.6 Flash does not improve in intelligence over 3.5 Flash
July 21, 2026