March 25, 2026
MiniMax M2.7: Everything you need to know
See model pageMiniMax has released MiniMax-M2.7, delivering GLM-5-level intelligence for less than one third of the cost
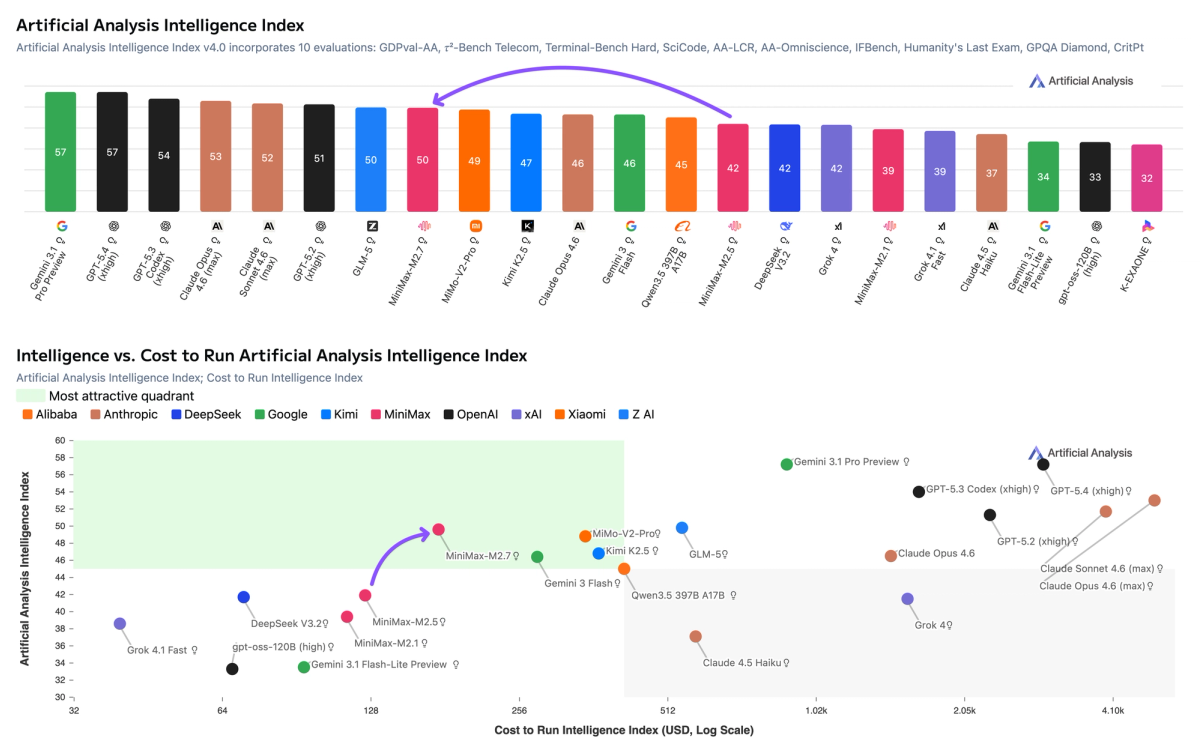
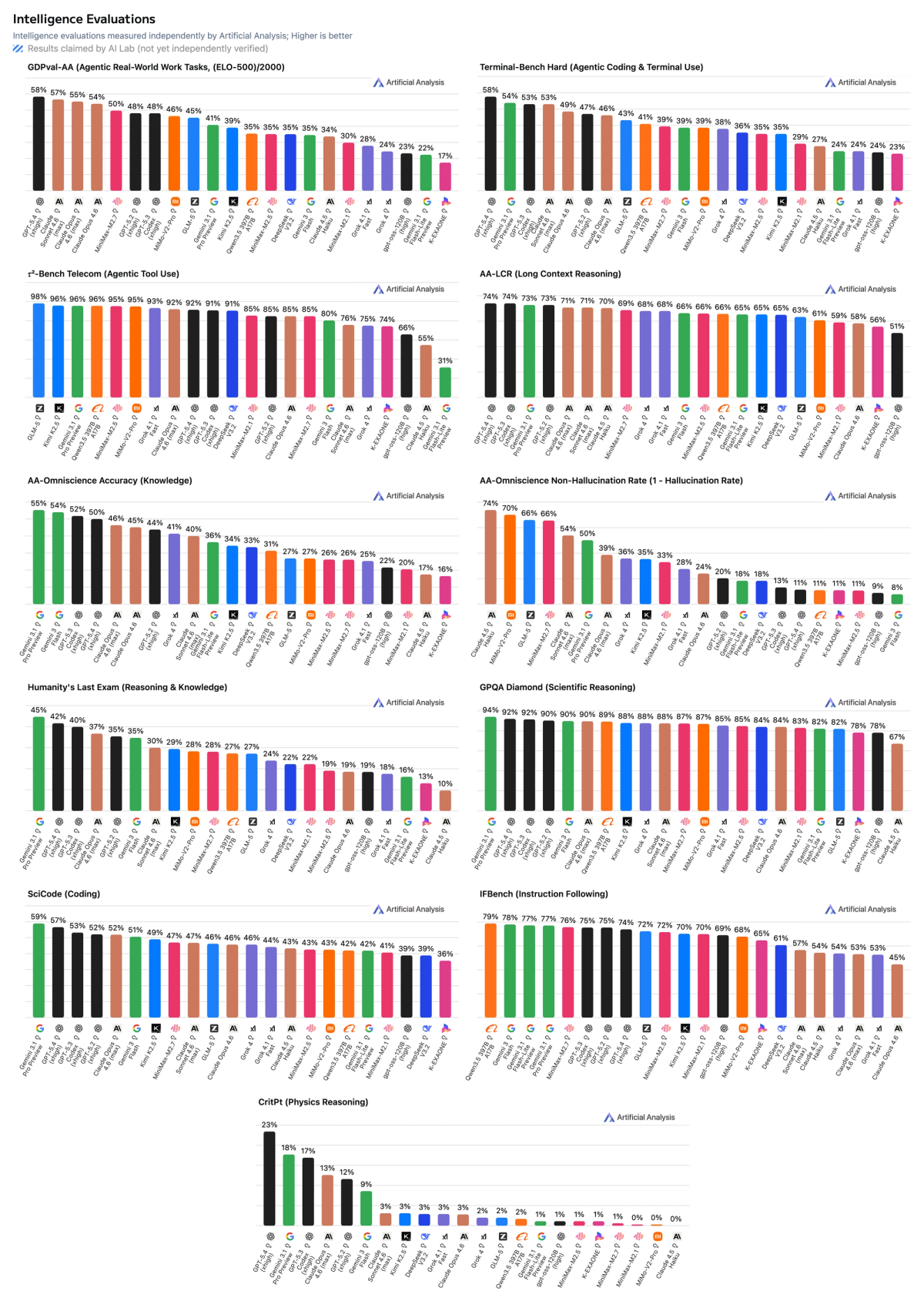
MiniMax-M2.7 from @MiniMax_AI scores 50 on the Artificial Analysis Intelligence Index, an 8-point improvement over MiniMax-M2.5, which was released one month ago. This is driven by stronger performance on real-world agentic tasks and reduced hallucinations. MiniMax-M2.7 is now ahead of MiMo-V2-Pro (Reasoning, 49) and Kimi K2.5 (Reasoning, 47), and equivalent to GLM-5 (Reasoning, 50) while using 20% fewer output tokens and costing less than a third as much to run. MiniMax-M2.7 is a reasoning-only model and maintains the same per-token pricing as MiniMax-M2.5.
Key takeaways:
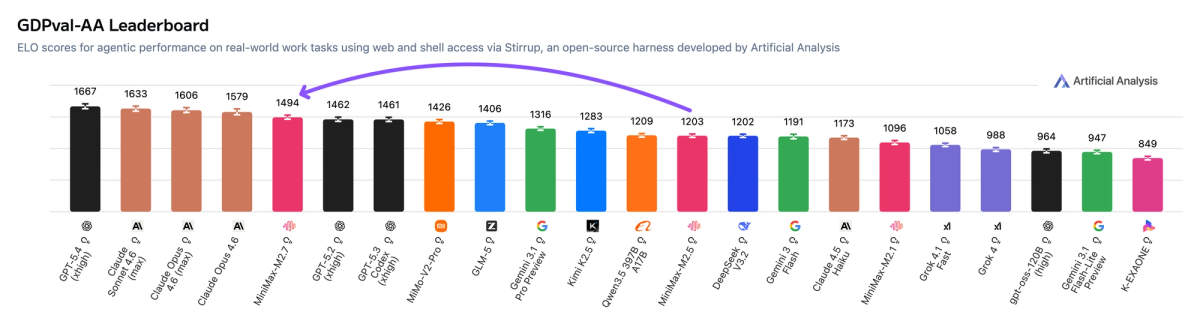
➤ Strong performance on real-world agentic tasks: MiniMax-M2.7 achieves a GDPval-AA Elo of 1494, a significant improvement from MiniMax-M2.5 (1203) and ahead of MiMo-V2-Pro (Reasoning, 1426), GLM-5 (Reasoning, 1406), and Kimi K2.5 (Reasoning, 1283). It remains behind frontier models such as GPT-5.4 (xhigh, 1667) and Claude Opus 4.6 (Adaptive Reasoning, max effort, 1606)
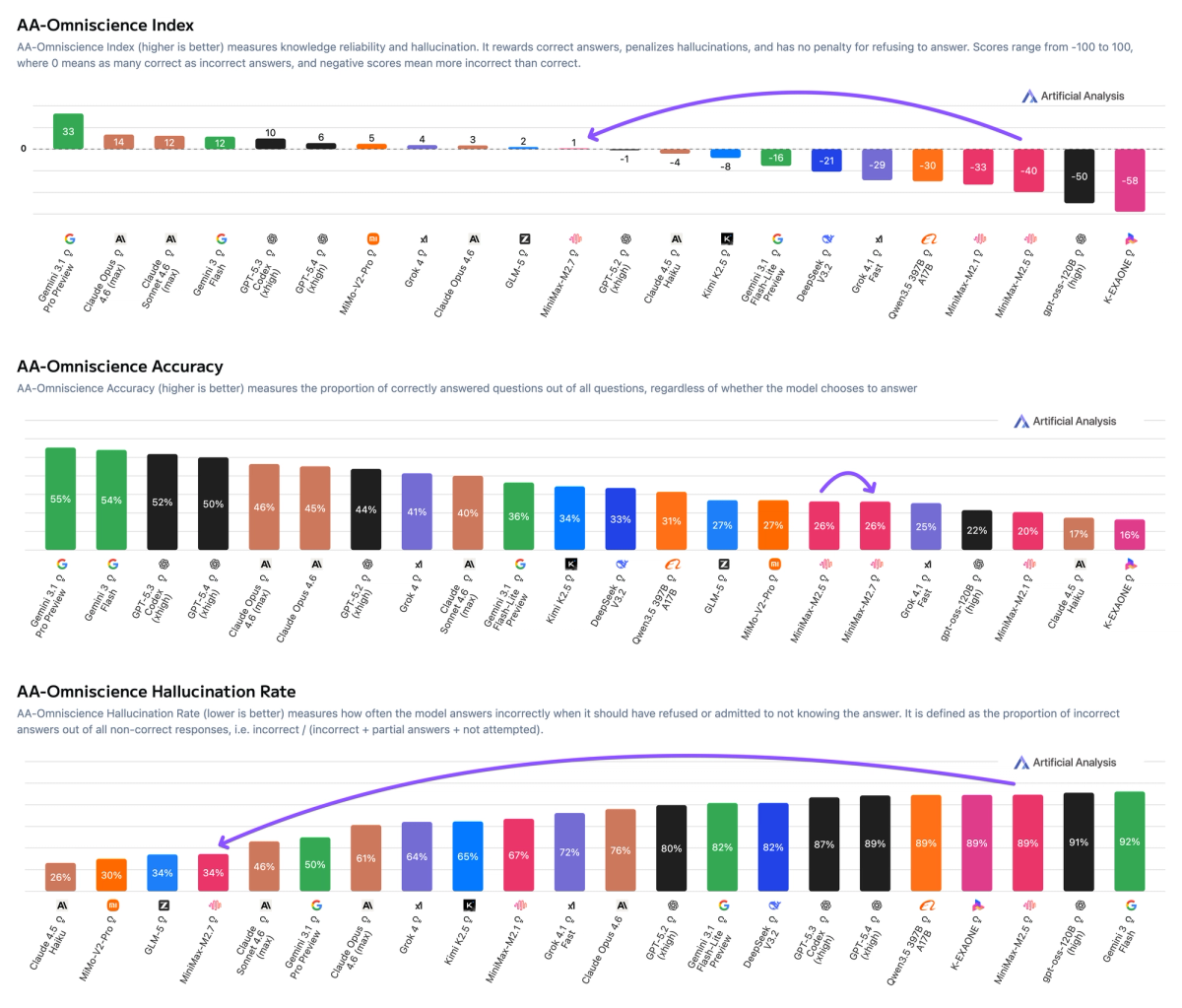
➤ Reduced hallucinations: MiniMax-M2.7 scores +1 on the AA-Omniscience Index, up from MiniMax-M2.5 (-40). This is competitive with GPT-5.2 (xhigh, -1) and GLM-5 (Reasoning, +2), and well ahead of Kimi K2.5 (Reasoning, -8). The improvement from M2.5 is purely driven by reduced hallucinations, meaning the model is more likely to abstain from answering when it doesn’t know the answer, rather than guessing. M2.7 achieves a hallucination rate of 34%, lower than Claude Sonnet 4.6 (Adaptive Reasoning, max effort, 46%) and Gemini 3.1 Pro Preview (50%).
➤ Gains across most evaluations compared to MiniMax-M2.5: Outside of the GDPval-AA and AA-Omniscience improvements noted above, MiniMax-M2.7 improves in HLE (+9 p.p.), TerminalBench Hard (+5 p.p.), SciCode (+4 p.p.), IFBench (+4 p.p.), GPQA (+3 p.p.), and LCR (+3 p.p.). We saw a notable regression in τ²-Bench (-11 p.p.).
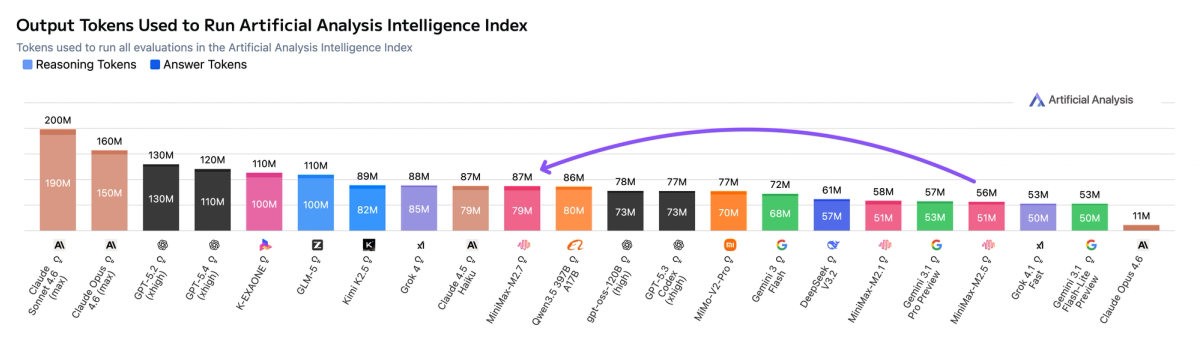
➤ Increased token use: MiniMax-M2.7 used ~87M output tokens to run the Artificial Analysis Intelligence Index, up 55% from MiniMax-M2.5 (~56M). It remains more token-efficient than other models such as GLM-5 (Reasoning, 110M) and Kimi K2.5 (Reasoning, ~89M)
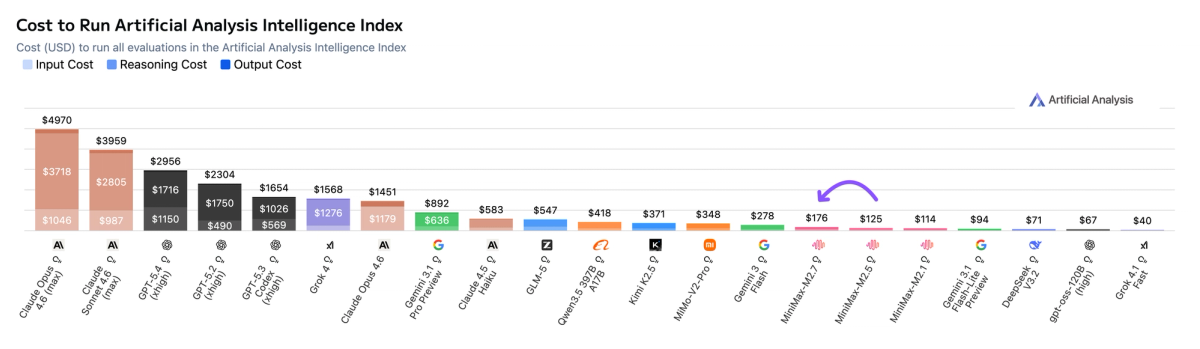
➤ Leading cost efficiency: MiniMax-M2.7 cost $176 to run the Artificial Analysis Intelligence Index, maintaining the same $0.30/$1.20 per 1M input/output pricing as M2.5. This places it on the Pareto frontier of our Intelligence vs. Cost chart. For context, GLM-5 (Reasoning) cost $547 at equivalent intelligence, Kimi K2.5 (Reasoning) cost $371, and Gemini 3 Flash Preview (Reasoning) cost $278
Key model details:
➤ Context window: 200K tokens (equivalent to MiniMax-M2.5).
➤ Pricing: $0.30/$1.20 per 1M input/output tokens (unchanged from MiniMax-M2.5).
➤ Availability: MiniMax first-party API only.
➤ Modality: Text input and output only (no multimodality).
➤ Licensing: MiniMax has not announced whether MiniMax-M2.7 will be open weights. MiniMax-M2.5 is available under the MIT license.
MiniMax-M2.7 achieves one of the highest scores in GDPval-AA (agentic real-world work tasks) with an Elo of 1495. This places it ahead of GPT-5.3 Codex (xhigh, 1462) and alongside GPT-5.2 (xhigh, 1462)
MiniMax-M2.7 scores +1 on the AA-Omniscience Index, up from MiniMax-M2.5 (-40). This improvement is purely driven by a reduction in hallucination rate to 34% (-55 p.p.), one of the lowest hallucination rates recorded. This means that the model is much more likely to abstain from answering when it doesn’t know the answer, rather than guessing.
MiniMax-M2.7 cost ~$175 to run the Artificial Analysis Intelligence Index at $0.30/$1.20 per 1M input/output tokens (unchanged from M2.5), making it less expensive than peer models at similar intelligence such as GLM-5 (Reasoning, ~$547), MiMo-V2-Pro (Reasoning, ~$348), and Kimi K2.5 (Reasoning, $371). This is an increase from M2.5 ($125), driven by higher output token usage.
MiniMax-M2.7 used ~87M output tokens to run the Artificial Analysis Intelligence Index, up 55% from MiniMax-M2.5 (~56M). Even so, it remains more token-efficient than GLM-5 (Reasoning, ~109M) and Kimi K2.5 (Reasoning, ~89M) at equivalent or lower intelligence. MiMo-V2-Pro (Reasoning, ~77M) used fewer tokens but at a lower Intelligence Index score.
Full breakdown of results:
Full results available on the MiniMax-M2.7 model page on Artificial Analysis: https://artificialanalysis.ai/models/minimax-m2-7
Read the latest

How Thinking Machines Lab’s Inkling performs on agentic knowledge work
Thinking Machines Lab’s Inkling scores an Elo of 836 on on our agentic knowledge work benchmark AA-Briefcase
July 22, 2026

Kimi K3: second only to Fable 5 on AA-Briefcase
Kimi K3 is second only to Fable 5 on AA-Briefcase, our agentic knowledge work benchmark, but costs more than Opus 4.8 to run while averaging nearly an hour per task
July 21, 2026

Gemini 3.6 Flash and Gemini 3.5 Flash-Lite: Halving Time per Task
Google has released Gemini 3.6 Flash and Gemini 3.5 Flash-Lite. Both halve time per task relative to their predecessors and increase token efficiency, Gemini 3.5 Flash-Lite improves by 11 Intelligence Index points while Gemini 3.6 Flash does not improve in intelligence over 3.5 Flash
July 21, 2026