May 28, 2026
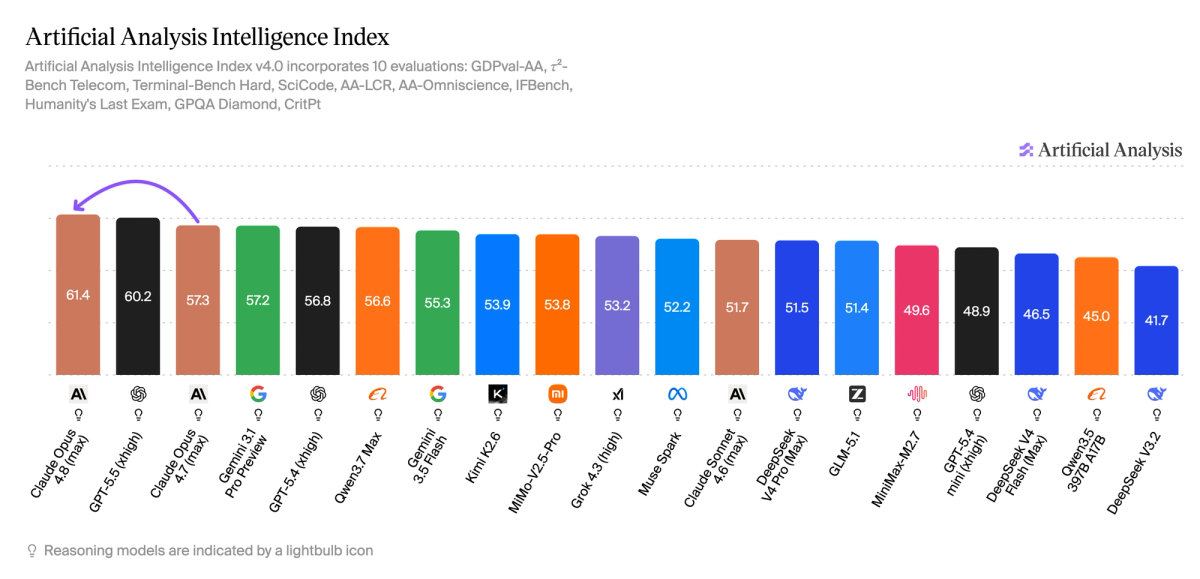
Claude Opus 4.8 takes the lead on the Artificial Analysis Intelligence Index
See model pageClaude Opus 4.8 takes the lead on the Artificial Analysis Intelligence Index at 61.4, with Anthropic retaking the #1 spot on GDPval-AA and advancing in terminal use and scientific reasoning.
To reach the leading position on the Intelligence Index, Anthropic made large improvements in both real-world agentic work and frontier academic reasoning tasks.
Key takeaways
- Claude Opus 4.8 is the new leader on the Artificial Analysis Intelligence Index. Opus 4.8 scores 61.4, up +4.1 points from Opus 4.7 and +1.2 points ahead of GPT-5.5 (xhigh), the previous Index leader.
- The new release is slightly more efficient than its predecessor on agentic tasks, but token efficiency varied by task type. We saw Opus 4.8 use fewer turns and output tokens on GDPval-AA, but approximately the same number of output tokens for the overall Intelligence Index to achieve significantly higher performance.
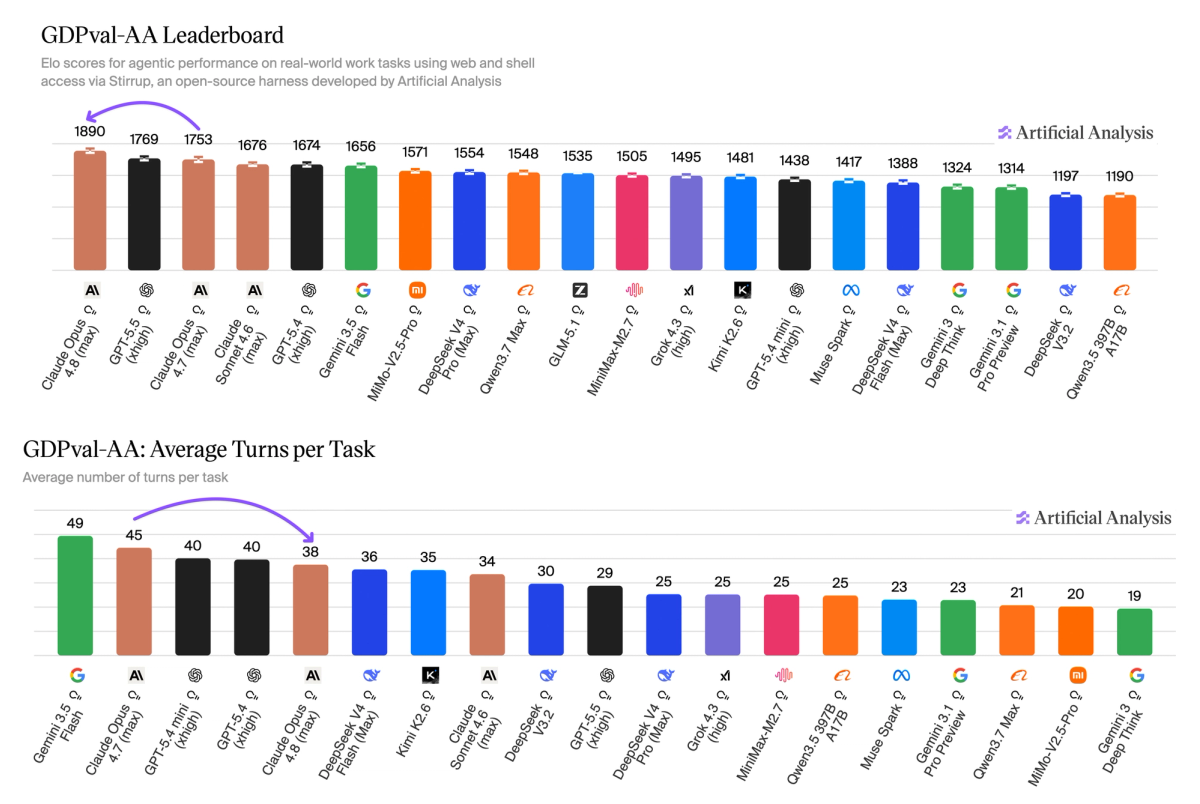
- Anthropic retakes the lead on GDPval-AA, our primary evaluation for agentic performance on knowledge work tasks. Opus 4.8 scored an 1,890 Elo, reflecting an implied win rate of approximately 67% against GPT-5.5.
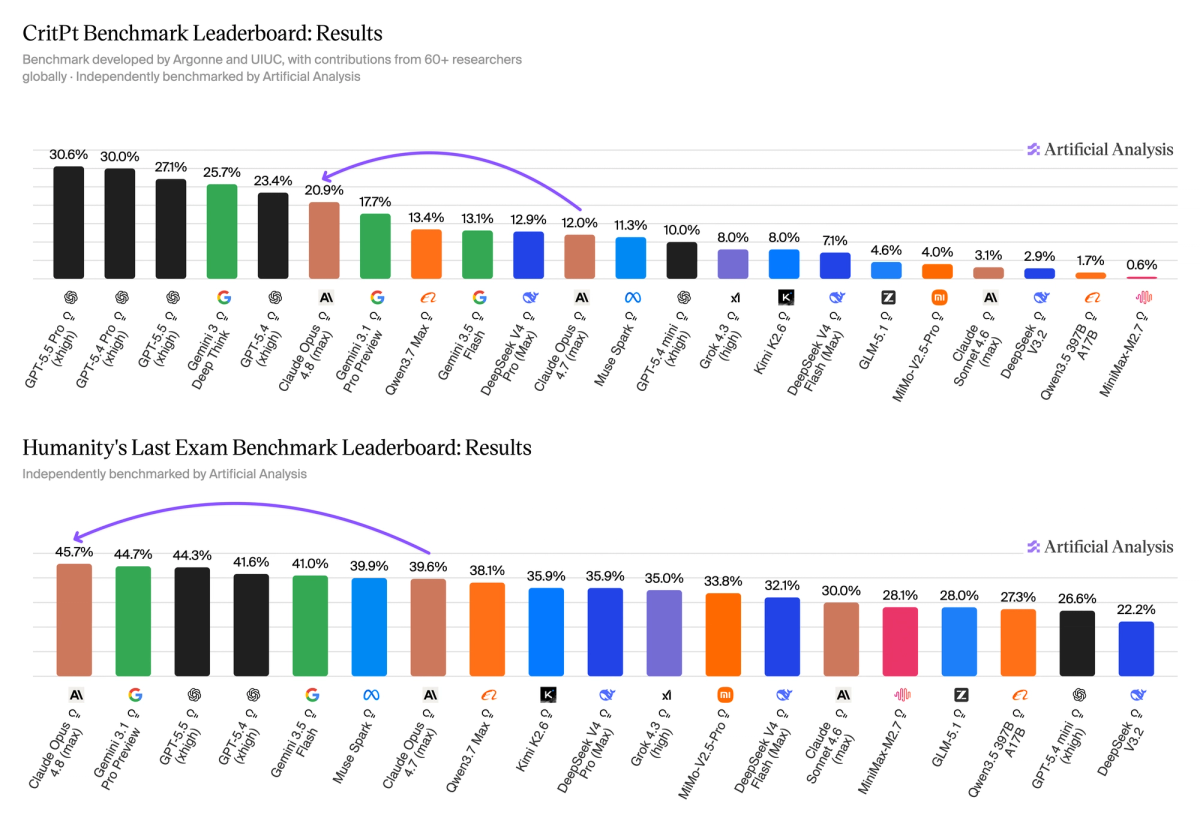
- Claude is now among the top models for scientific reasoning. Previous releases have trailed peers on complex academic reasoning tasks, but with Opus 4.8, Claude sits slightly ahead of OpenAI and Google as the leader on Humanity's Last Exam. It also scores higher than Gemini 3.1 Pro on CritPt, a frontier physics benchmark, but remains behind GPT-5.4 and GPT-5.5.
- Claude Opus 4.8 reaches #2 on AA-Omniscience, slightly ahead of Opus 4.7. Opus 4.8 scores 27.4 on the AA-Omniscience Index, behind only Gemini 3.1 Pro (32.9). Accuracy ticked up slightly to 46.6% and hallucination rate held roughly flat at 35.9%. Anthropic continues to demonstrate substantially lower hallucination rates than peer models from Google and OpenAI.
- Compared with Opus 4.7, Opus 4.8 also makes material gains on Terminal-Bench Hard (+6.8 points), τ²-Bench Telecom (+5.9 points), and IFBench (+3.6 points), with relatively flat scores across AA-LCR, GPQA, and SciCode.
Other key model details remain the same as Opus 4.7
- Context window of 1 million tokens (equivalent to Opus 4.7)
- Pricing of $5/$25 per million tokens of input/output; cache pricing remains at a 25% premium for cache writes ($6.25 per million tokens) with 5-minute time to live, and 90% discount for cache hits ($0.5 per million tokens)
- Effort remains the recommended way of configuring model performance and latency, with the same options as Opus 4.7. We measured the model at its 'max' effort setting to test peak performance.
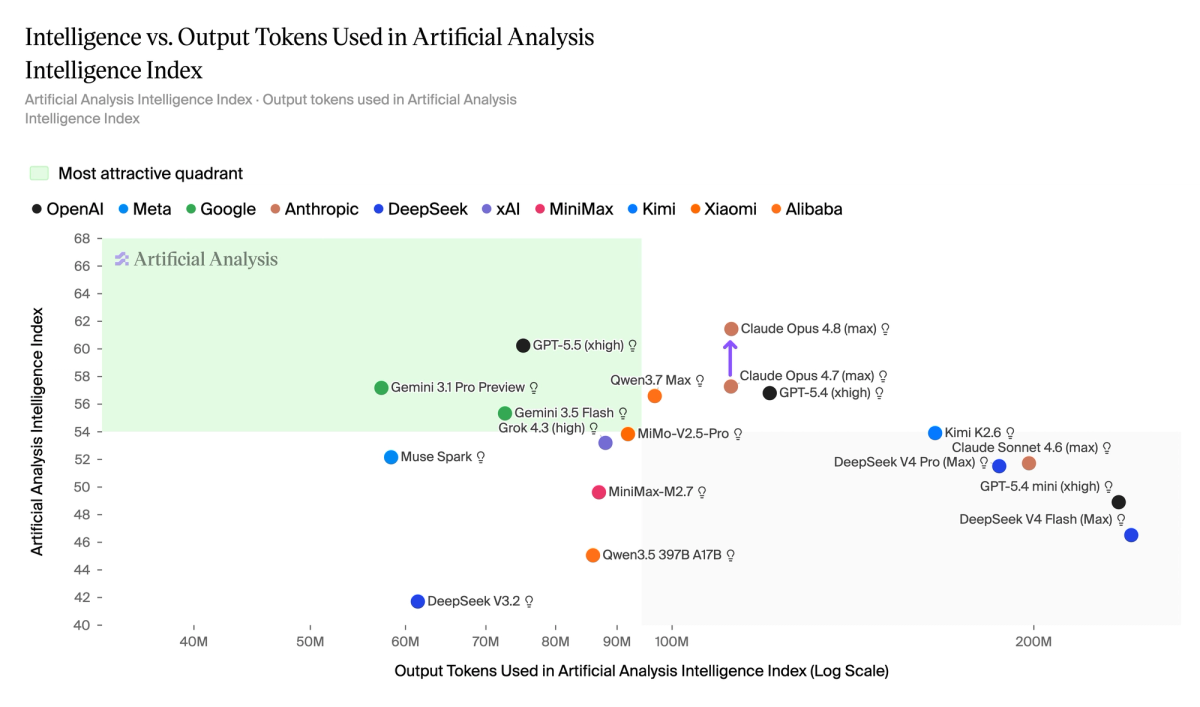
Intelligence vs output tokens
Across the overall Intelligence Index, Claude Opus 4.8 used approximately the same number of output tokens as Opus 4.7, but made substantial improvements in performance on a range of benchmarks across domains to achieve an Artificial Analysis Intelligence Index increase of 4 points.
Scientific and academic reasoning
Claude Opus 4.8 makes large strides in scientific and academic reasoning capabilities. It leads Humanity's Last Exam by 1 point in a tight contest between Anthropic, Google DeepMind, and OpenAI, and Claude Opus has overtaken Gemini 3.1 Pro on CritPt, a frontier physics evaluation developed by Argonne and UIUC.
GDPval-AA
Opus 4.8 scored 1,890 on GDPval-AA at launch with its 'max' effort setting, +137 points from Opus 4.7 and +121 points ahead of the next-best model, GPT-5.5 xhigh. Compared head-to-head on the GDPval task set, this implies a ~67% win rate against GPT-5.5 xhigh. It achieves this performance in 15% fewer turns per task and with 35% fewer output tokens than Opus 4.7. However, it still uses approximately 30% more turns than OpenAI's GPT-5.5, the second-ranked model.
Full results
Breakdown of full results for Claude Opus 4.8.
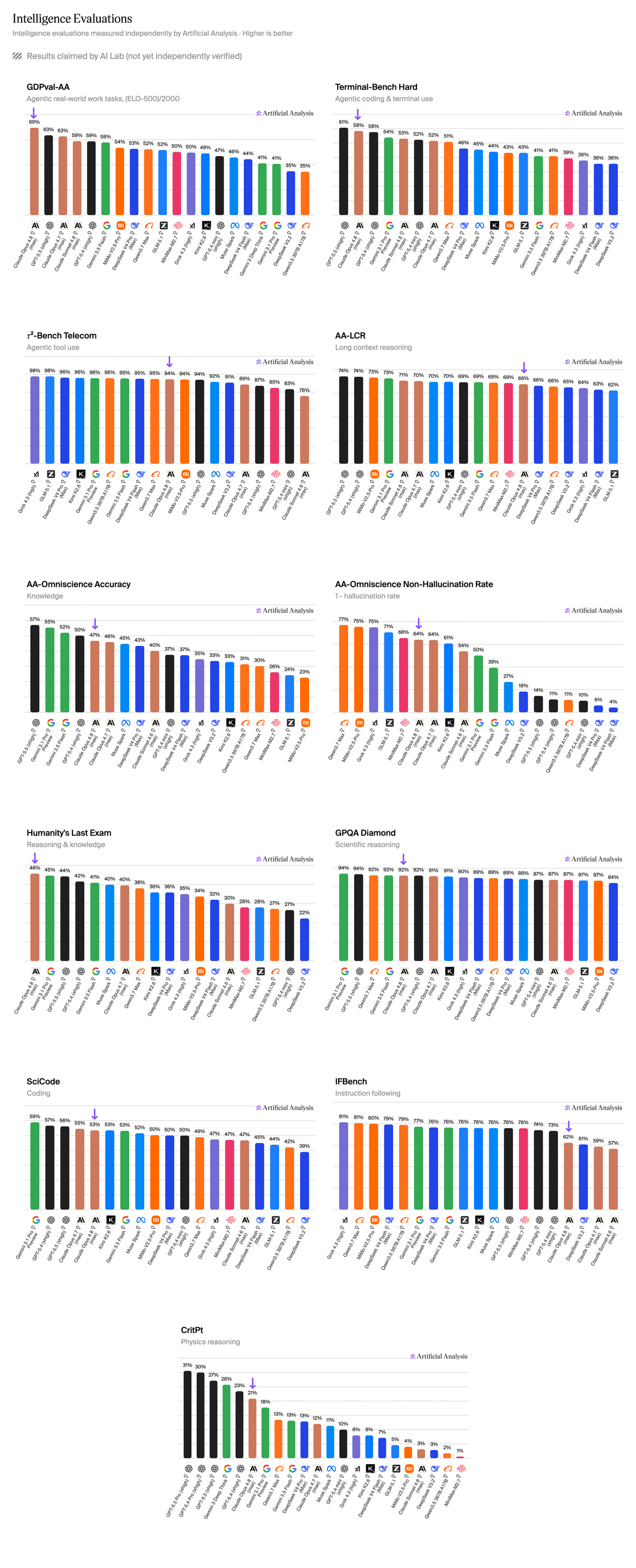
Further Benchmarks
Compare Opus 4.8 with other leading models at: https://artificialanalysis.ai/models/claude-opus-4-8
Read the latest

Claude Opus 5: the new leader in agentic knowledge work
Claude Opus 5 is the new leader on our agentic knowledge work benchmark, AA-Briefcase, outperforming Claude Fable 5 by nearly 150 Elo while reducing Cost per Task by 20%
July 24, 2026

Opus 5: Fable 5 level intelligence at a lower cost per task
Claude Opus 5 is narrowly the most intelligent model on the Artificial Analysis Intelligence Index, offering comparable intelligence to Fable 5 at 26% lower Cost per Task
July 24, 2026

How Thinking Machines Lab’s Inkling performs on agentic knowledge work
Thinking Machines Lab’s Inkling scores an Elo of 836 on on our agentic knowledge work benchmark AA-Briefcase
July 22, 2026