June 15, 2026
Announcing Artificial Analysis Intelligence Index v4.1: a shift toward agentic workloads, featuring upgraded benchmarks and new per-task metrics
The Artificial Analysis Intelligence Index is our synthesis metric for assessing model intelligence and tracking AI progress. v4.1 marks a broader shift toward agentic workloads, with three main changes:
Updated and reweighted evaluations toward agentic tasks:
- We upgraded three evaluations, removed one, and reweighted the Intelligence Index:
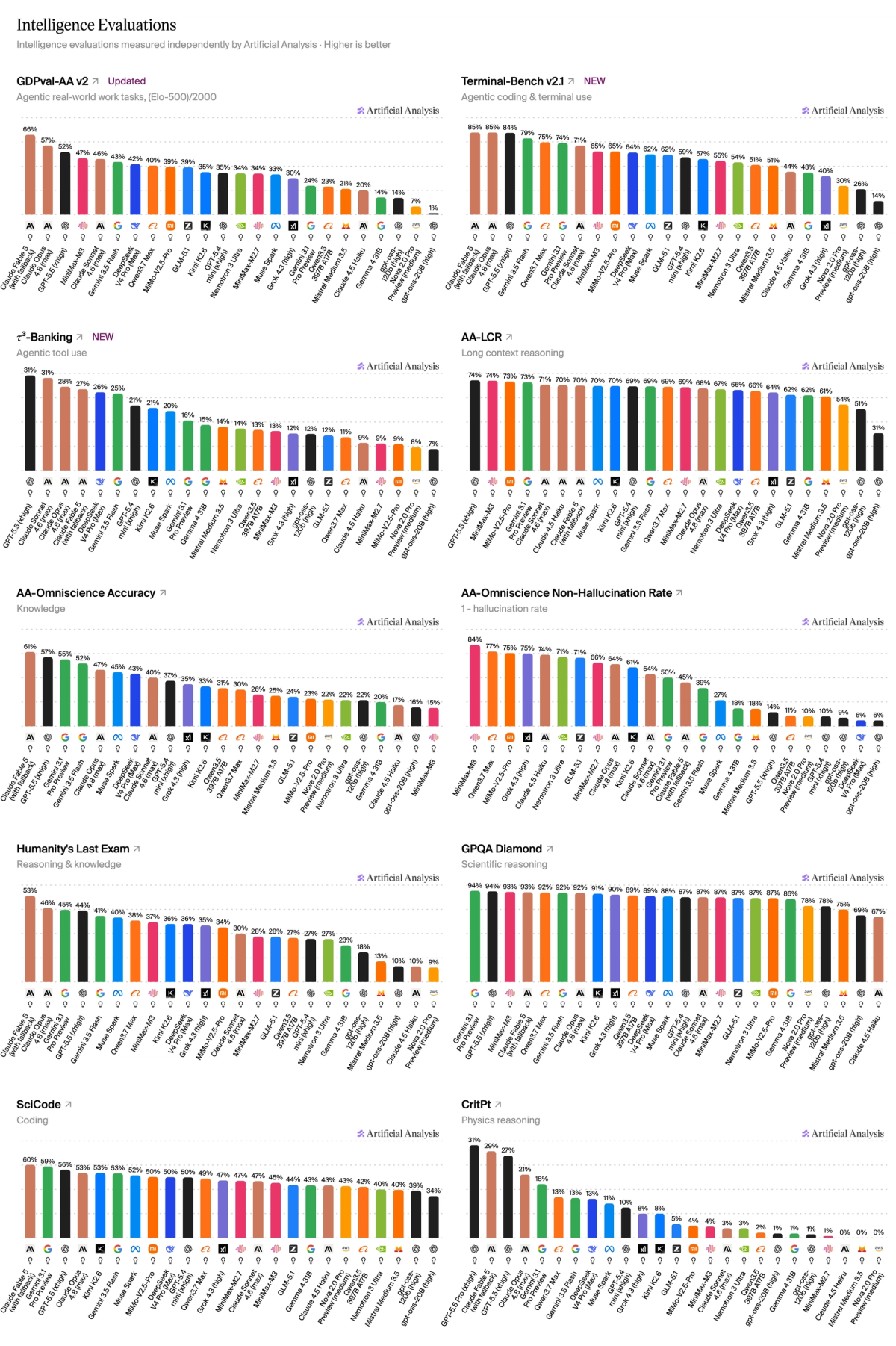
- Upgraded Terminal-Bench Hard to Terminal-Bench 2.1 and τ²-Bench Telecom to τ³-Bench Banking. Both move to newer, more robust task sets with harder, more realistic agentic scenarios that better separate frontier models
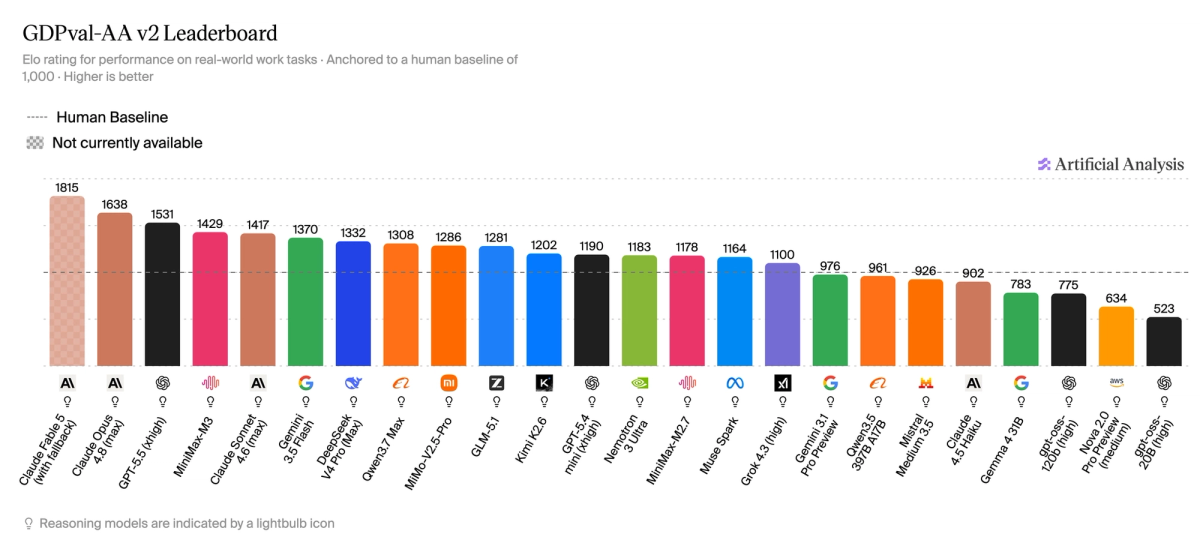
- Upgraded GDPval-AA to GDPval-AA v2. The upgrade re-baselines Elo to human performance at 1000, introduces a rotating panel of frontier-model judges, and raises the turn limit from 100 to 250 for longer-horizon agent trajectories
- Removed IFBench due to saturation. The benchmark no longer distinguishes frontier models sufficiently, so we have removed it from the Intelligence Index. We will continue to run it and publish results on new model releases
-
Cost per Task, Time per Task, and Tokens per Task: Three new per-task metrics, reported for every model and based on the Intelligence Index. We take the total cost, total time, and total output tokens for a model to run the Intelligence Index and divide by the number of tasks across its evaluations, giving the average cost, time, and output tokens to complete a single Intelligence Index task
-
Cached input token reporting: We now report cached input tokens and their impact on cost, including the cost to run the Intelligence Index, to better reflect the real cost of running each model
Key Results:
- Leading models: Claude Fable 5 (with Opus 4.8 fallback, 60) leads the Artificial Analysis Intelligence Index v4.1 by four points but is currently unavailable, leaving Claude Opus 4.8 (max, 56) as the most intelligent available model, ahead of GPT-5.5 (xhigh, 55)
- Open weights leading models: Among open weights models, DeepSeek V4 Pro (max, 44) and MiniMax M3 (44) lead, followed by Kimi K2.6 (43) and MiMo-V2.5-Pro (42)
- Cost per Task: Claude Opus 4.8 (max) is the most expensive available model at $1.78 per task, with Claude Fable 5 the highest overall at $3.25. GPT-5.5 (xhigh) scores within a point of Opus 4.8 on the Intelligence Index at $0.99 per task. DeepSeek V4 Pro (max) stands out on the Intelligence vs Cost per Task chart at $0.04 per task, with other leading proprietary models costing 20x to 45x more
- Time per Task: time per task (inference decode time) ranges from 1.5 minutes for Grok 4.3 (high) to 13.5 for Claude Sonnet 4.6 (max), a roughly 9x spread. Claude Opus 4.8 (max) completes a task in 6.4 minutes and GPT-5.5 (xhigh) in 3.7, while Gemini 3.1 Pro Preview stands out on the Intelligence vs Time per Task chart at 1.6 minutes for a score of 46
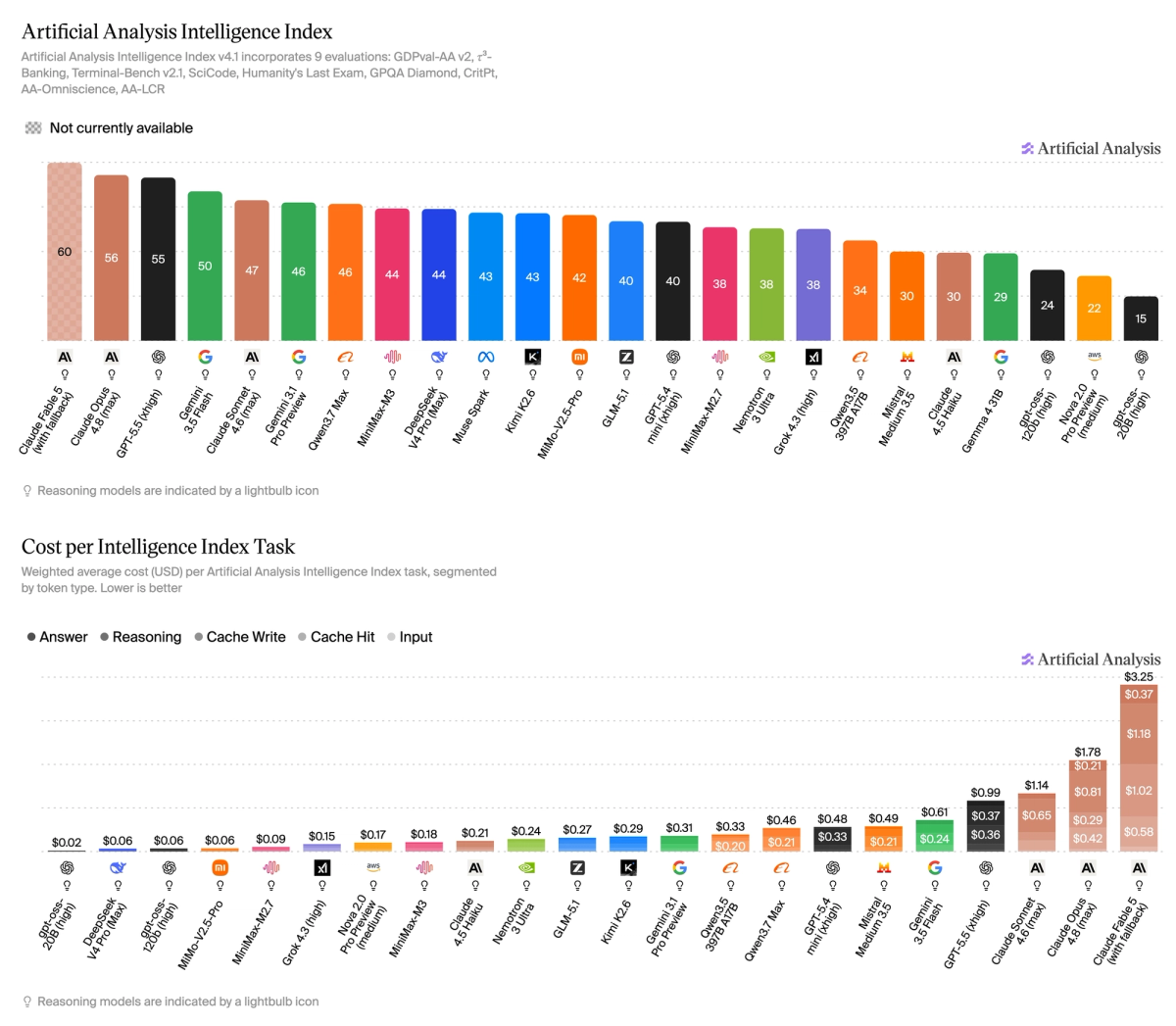
DeepSeek V4 Pro (max) stands out on the Intelligence vs Cost per Task chart at $0.04 per task for an Intelligence Index of 44, running a single Intelligence Index task over 20x cheaper than GPT-5.5 (xhigh, $0.99) and over 40x cheaper than Claude Opus 4.8 (max, $1.78)
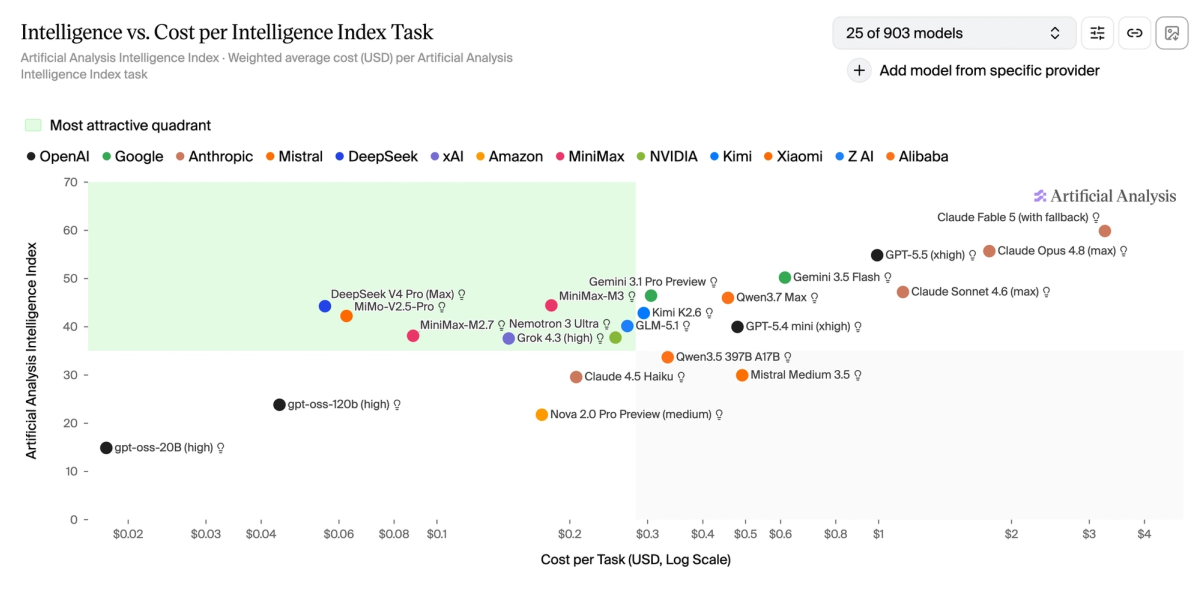
Time per Intelligence Index task for leading models ranges from 1.5 minutes for Grok 4.3 (high) to 13.5 minutes for Claude Sonnet 4.6 (max). Claude Sonnet 4.6 takes longer per task than Claude Opus 4.8 (max) because it uses more output tokens to run the Intelligence Index. Gemini 3.1 Pro Preview stands out on the Intelligence vs Time per Intelligence Index Task chart at 1.6 minutes for an Intelligence Index of 46
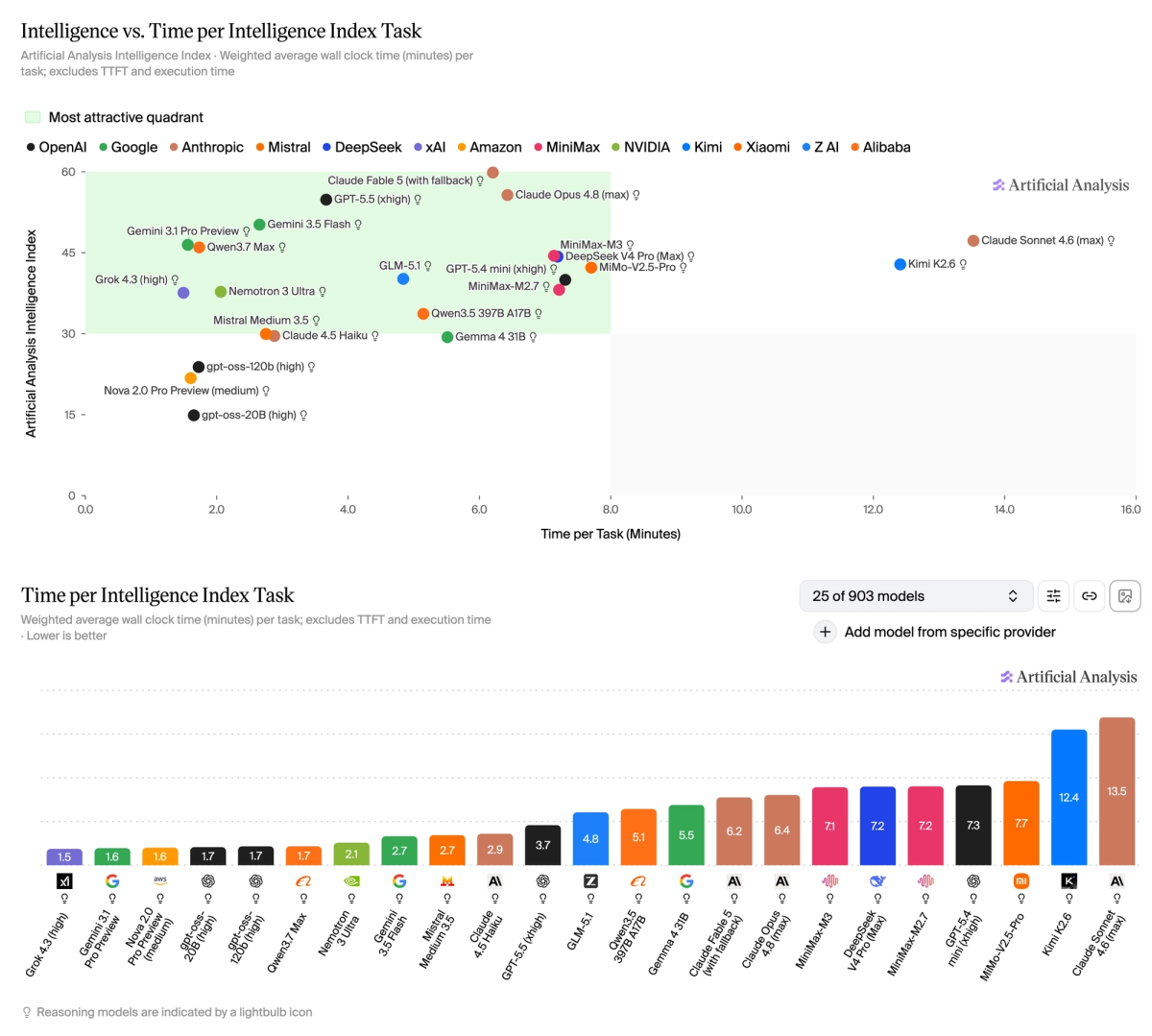
GDPval-AA v2 is the highest weighted evaluation in the Intelligence Index v4.1. The upgrade re-baselines ELO to human performance at 1000, introduces a rotating panel of frontier-model judges, and raises the turn limit from 100 to 250 for longer-horizon agent trajectories. Claude Fable 5 (with fallback) leads at 1818, followed by Claude Opus 4.8 (1638). GPT-5.5 (xhigh) scores 1531. Claude Fable 5 is not currently available for use
Full Intelligence Index v4.1 weights:
- GDPval-AA v2: 20%
- Terminal-Bench 2.1: 16%
- τ³-Bench Banking: 14%
- Humanity's Last Exam: 12%
- AA-Omniscience Accuracy: 8%
- SciCode: 8%
- GPQA: 6%
- AA-LCR: 6%
- CritPt: 6%
- AA-Omniscience Non-Hallucination: 4%
Read the latest

Claude Opus 5: the new leader in agentic knowledge work
Claude Opus 5 is the new leader on our agentic knowledge work benchmark, AA-Briefcase, outperforming Claude Fable 5 by nearly 150 Elo while reducing Cost per Task by 20%
July 24, 2026

Opus 5: Fable 5 level intelligence at a lower cost per task
Claude Opus 5 is narrowly the most intelligent model on the Artificial Analysis Intelligence Index, offering comparable intelligence to Fable 5 at 26% lower Cost per Task
July 24, 2026

How Thinking Machines Lab’s Inkling performs on agentic knowledge work
Thinking Machines Lab’s Inkling scores an Elo of 836 on on our agentic knowledge work benchmark AA-Briefcase
July 22, 2026