February 5, 2026
Opus 4.6 Takes Lead in Agentic Real-World Knowledge Tasks
We worked with Anthropic to benchmark Claude Opus 4.6 ahead of launch — it reached an Elo of 1606 with adaptive thinking, nearly 150 points ahead of GPT-5.2 (xhigh). This implies a win rate of ~70% when compared head-to-head with OpenAI's December 2025 flagship.
Using ~160 million tokens in adaptive thinking mode to complete the 220 tasks in GDPval-AA, Claude Opus 4.6 used 30–60% more tokens than Opus 4.5, but still far fewer than GPT-5.2 (xhigh). This increased token use combined with its high per-token pricing ($5/$25 per million tokens, no change from Opus 4.5) makes Claude Opus 4.6 the most costly model we've tested on GDPval-AA so far.
See below for a breakdown of token use, turns and cost, along with example file outputs.
The full set of Artificial Analysis Intelligence Index benchmarks are in progress — we will share a full update on the performance of Opus 4.6 when complete.
GDPval-AA is our primary metric for general agentic performance, measuring the performance of models on knowledge work tasks from preparing presentations and data analysis through to video editing. Models use shell access and web browsing in an agentic loop through Stirrup, our open-source agentic reference harness.
The underlying GDPval dataset was released by OpenAI in September 2025 to capture self-contained work tasks across 44 occupations in 9 different sectors. It offers insight into the types of tasks models can complete that are relevant to today's workforce, and is highly realistic due to the OpenAI team's expert filtering and curation.
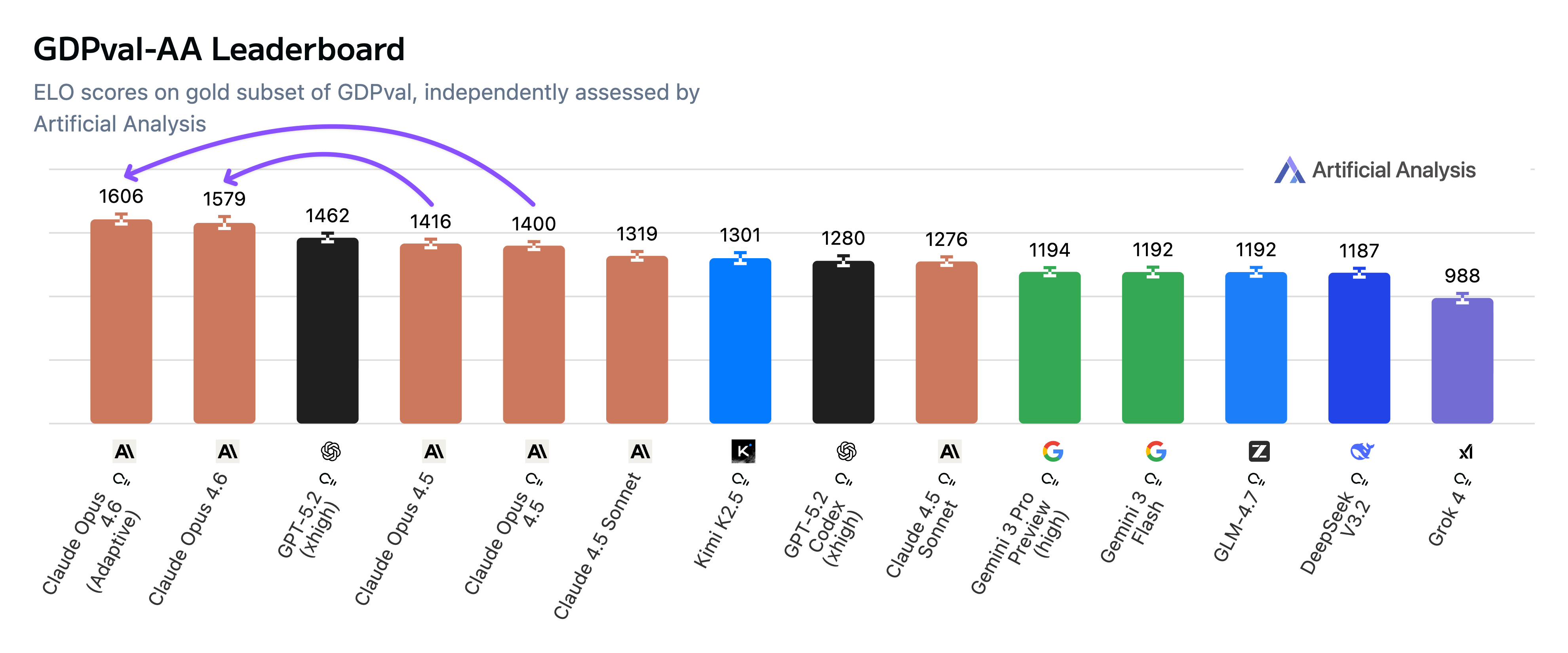 Claude Opus 4.6 reaches an Elo of 1606 on the GDPval-AA Leaderboard, nearly 150 points ahead of GPT-5.2 (xhigh)
Claude Opus 4.6 reaches an Elo of 1606 on the GDPval-AA Leaderboard, nearly 150 points ahead of GPT-5.2 (xhigh)
Claude Opus 4.6 uses both more tokens and turns to achieve this performance improvement (in both the non-reasoning and adaptive reasoning with max effort configs that we tested). It used 30–60% more tokens than Opus 4.5, but still far fewer than GPT-5.2 (xhigh). Along with higher token usage, Opus 4.6 made more extensive use of the image viewer tool to 'see' its work than its predecessor — this enables it to check its work and iterate, an important capability for working on tasks in Stirrup, as well as other agentic products like Claude Code and Claude Cowork.
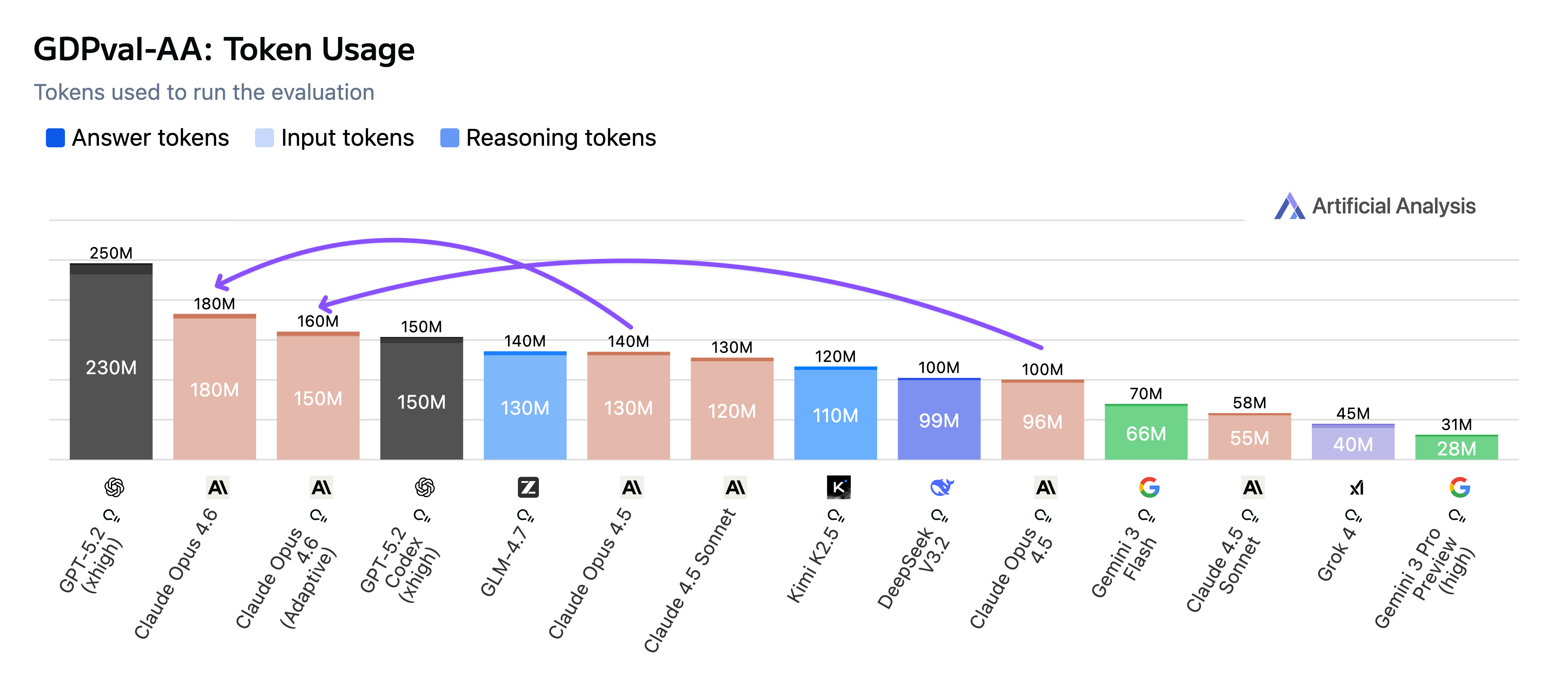 Claude Opus 4.6 used 30–60% more tokens than Opus 4.5, but still far fewer than GPT-5.2 (xhigh)
Claude Opus 4.6 used 30–60% more tokens than Opus 4.5, but still far fewer than GPT-5.2 (xhigh)
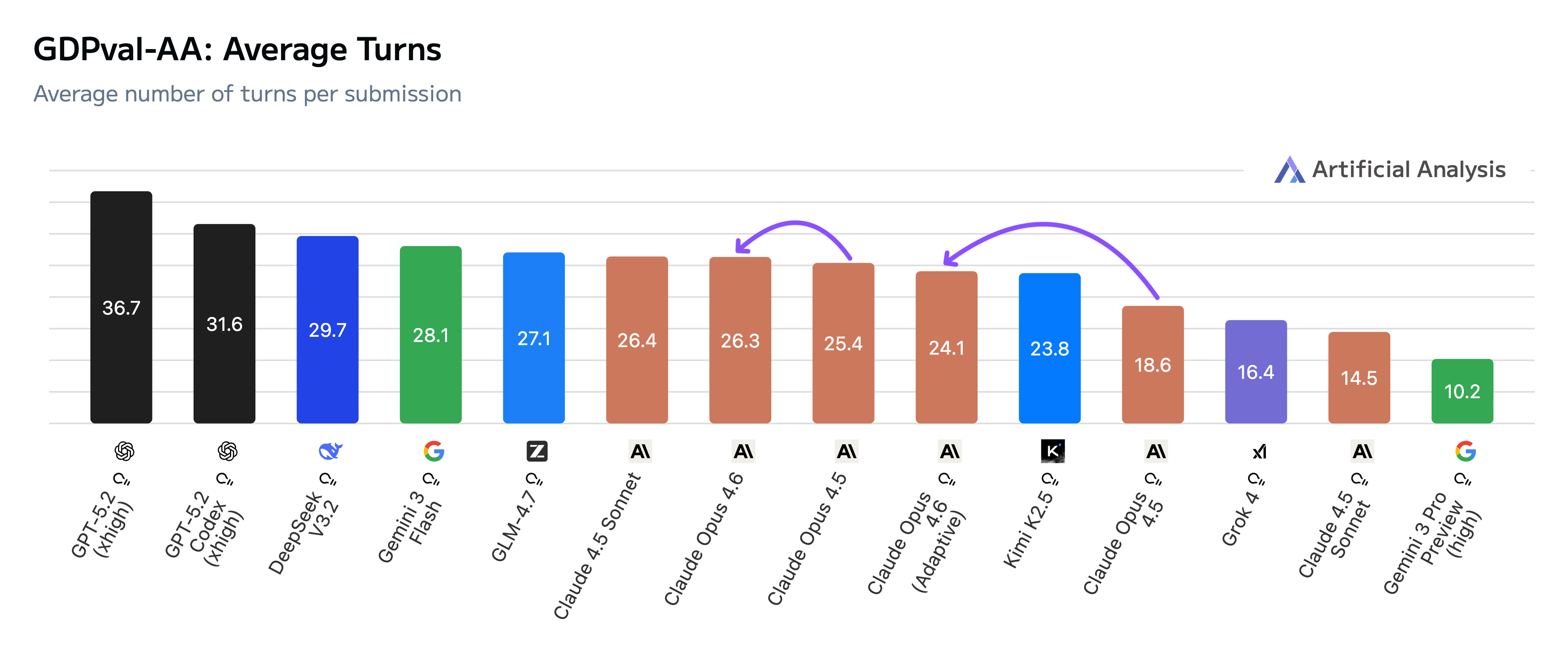 Claude Opus 4.6 uses more turns per task than Opus 4.5, reflecting its iterative approach to checking and refining its work
Claude Opus 4.6 uses more turns per task than Opus 4.5, reflecting its iterative approach to checking and refining its work
Claude Opus 4.6 is the most costly model to complete GDPval-AA so far due to its increased token usage and pricing remaining at $5/$25 per million tokens of input/output (before accounting for cached token discounts). Despite the high cost, its first place performance places it firmly on the Pareto frontier for performance versus cost on GDPval-AA.
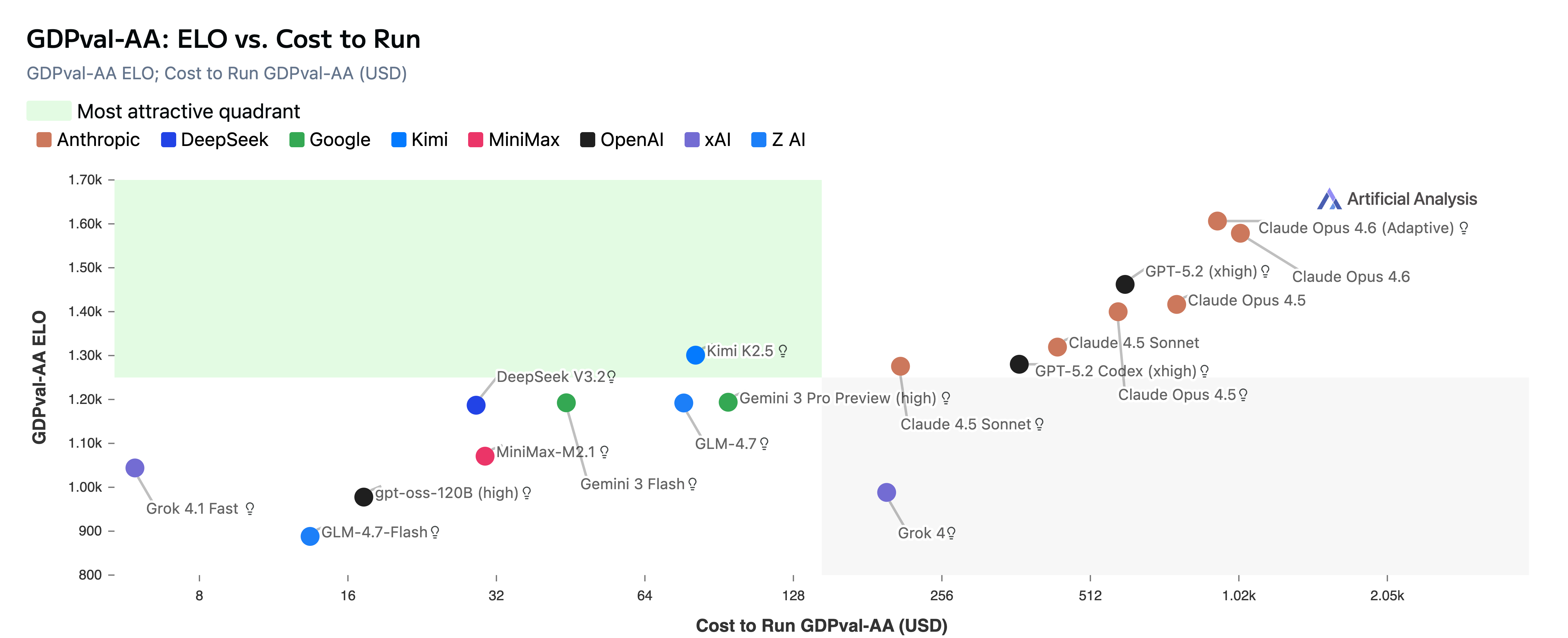 Despite the high cost, Claude Opus 4.6's first place performance places it on the Pareto frontier for ELO versus cost on GDPval-AA
Despite the high cost, Claude Opus 4.6's first place performance places it on the Pareto frontier for ELO versus cost on GDPval-AA
Claude Opus 4.6 showed notable results on visual understanding and aesthetics. This task example shows the generation of a video production schedule. Compared to other leading models, Opus 4.6 uses more professional-looking visual elements and layout. Other models produce 'functional' but limited schedules — for example, GPT-5.2 produces a more simplistic table-based schedule that does not make use of the full PDF page submitted. We're publishing a further set of three example files on the GDPval-AA leaderboard on our website.
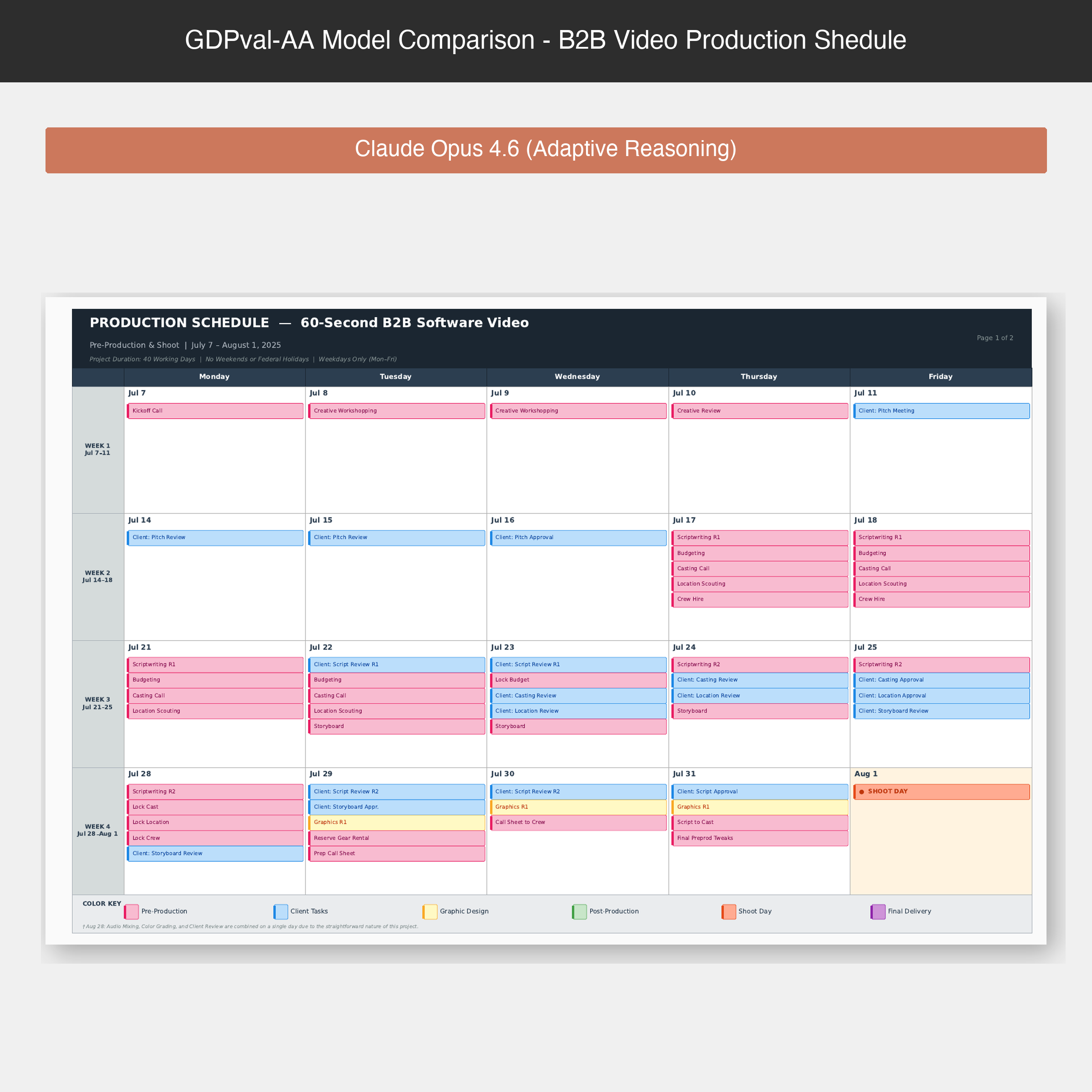 Claude Opus 4.6 produces a professional-looking production schedule with color-coded visual elements and structured layout
Claude Opus 4.6 produces a professional-looking production schedule with color-coded visual elements and structured layout
 GPT-5.2 (xhigh) produces a more simplistic table-based production schedule
GPT-5.2 (xhigh) produces a more simplistic table-based production schedule
 Gemini 3 Pro Preview (high) generates a calendar-style production schedule with color-coded categories
Gemini 3 Pro Preview (high) generates a calendar-style production schedule with color-coded categories
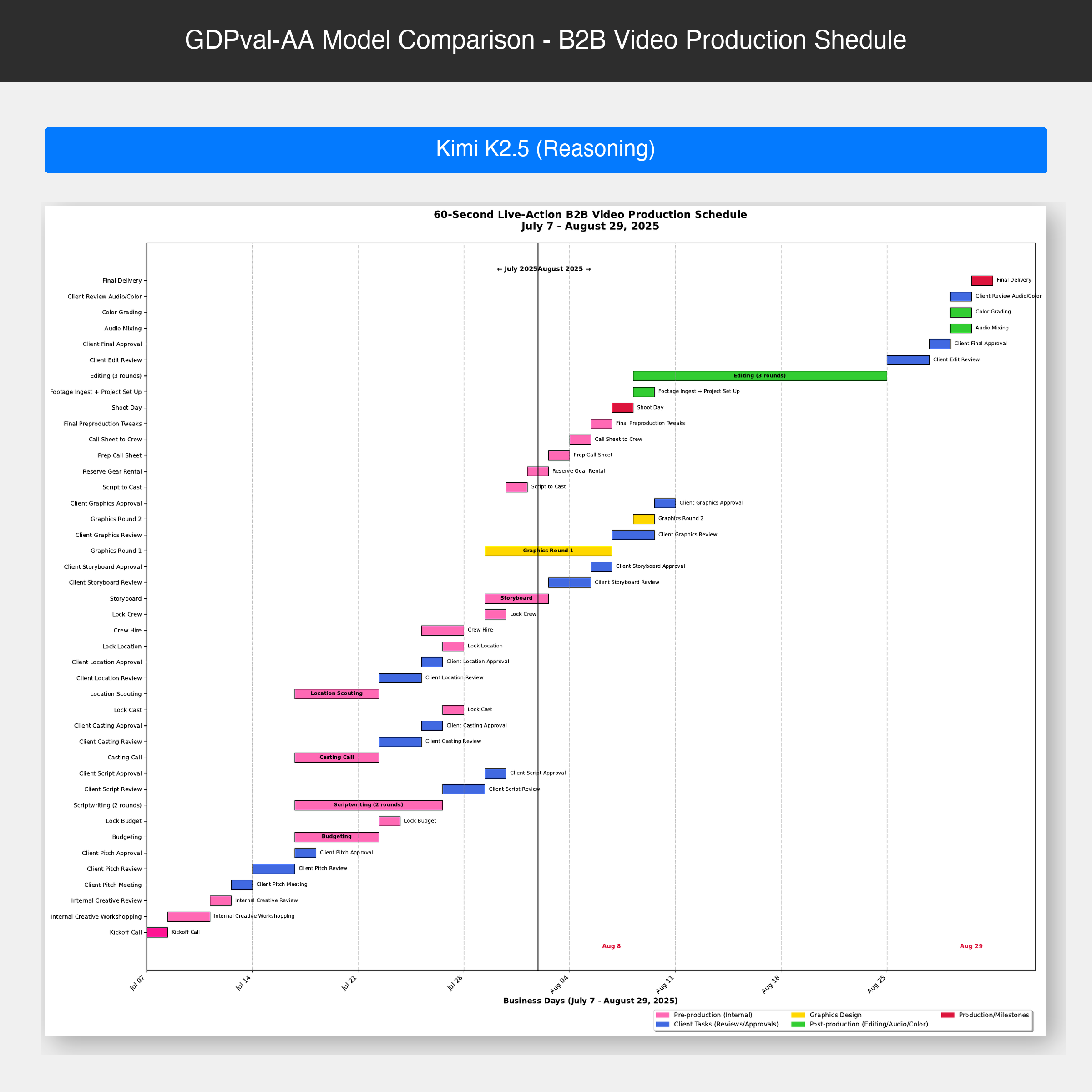 Kimi K2.5 (Reasoning) creates a detailed Gantt chart-style production schedule
Kimi K2.5 (Reasoning) creates a detailed Gantt chart-style production schedule
View GDPval-AA comparisons in depth on the GDPval-AA leaderboard on the Artificial Analysis website.