February 7, 2026
Opus 4.6: Everything You Need to Know
Claude Opus 4.6 takes first place in the full Artificial Analysis Intelligence Index, but used ~2x more output tokens than Claude Opus 4.5 in its max effort mode
Key takeaways:
➤Opus 4.6 is the clear leader in the Artificial Analysis Intelligence Index, our synthesis metric that incorporates 10 evaluations covering capabilities including agentic tasks, coding and scientific reasoning.
➤Opus 4.6 is winning in 3 of our evaluations: GDPval-AA (Agentic Real-World Work Tasks), TerminalBench (Agentic Coding & Terminal Use) and CritPT (Research-level Physics Problems).
➤Opus 4.6 scored highest in most evaluations in its adaptive thinking with max effort mode, except in TerminalBench where the non-thinking mode achieved the highest score (49% vs 46%). Opus 4.6 makes small gains across other evals, but does not achieve new #1 scores. We saw a large gain in HLE (+8 p.p.), and small gains in GPQA (+3 p.p.), SciCode (+2.3 p.p.) and Tau2 (+3 p.p.). We saw small regressions in AA-LCR (Long Context Reasoning) (-3 p.p.), IFBench (-5 p.p.), and Omniscience Hallucination Rate (+2 p.p.).
➤Opus 4.6 (in adaptive thinking mode with max effort) cost $2,486 to run the Artificial Analysis Intelligence Index. This is more expensive than OpenAI’s GPT-5.2 (xhigh), the previous Intelligence Index leader, which cost $2,304. However, this does not account for cached input token discounts offered by Anthropic and others - we will be incorporating these into our Intelligence Index cost calculations in the near future.
➤Opus 4.6 used significantly more tokens than Opus 4.5: it used 58M output tokens in adaptive thinking mode to run our Intelligence Index evaluations, ~2x Opus 4.5 (Thinking, 29M) but significantly less than GPT-5.2 with xhigh reasoning effort (130M).
➤Opus 4.6 is priced identically to Opus 4.5 ($5/$25 per 1M input/output tokens). This high price compared to competitors means that despite Opus 4.6 still being relatively token efficient compared to other frontier models, its overall cost is high.
➤Anthropic has made several key changes in the release of Opus 4.6:
➤Opus 4.6 introduces a new ‘adaptive thinking’ mode, which will replace Anthropic’s previous ‘extended thinking’ mode for future models. Instead of setting a confusing ‘thinking token budget’, developers can now control the model’s thinking with the ‘effort’ setting (with ‘low’, ‘medium’, ‘high’ and ‘max’ settings - we evaluated adaptive thinking with max effort). Anthropic are promoting ‘adaptive thinking’ mode as enabling Opus 4.6 to more dynamically decide how long to think for, and recommending developers migrate to it alongside upgrading to Opus 4.6.
➤Opus 4.6’s context window has been expanded to 1 million tokens, positioning it competitively with Gemini 3 Pro for ultra-long context tasks (similar to recent Sonnet releases) - although Anthropic frames this feature as currently ‘in beta’.
➤Compared to Opus 4.5, Opus 4.6’s maximum output tokens limit has doubled from 64,000 to 128,000 tokens.
Key model details:
➤Context window: 1M tokens (currently in beta) and 5x Opus 4.5’s context window (200K)
➤Max output tokens: 128K tokens (vs. Opus 4.5’s 64K max output tokens)
➤Availability: Claude Opus 4.6 is available via Anthropic's API, @GoogleCloudTech Vertex, AWS Bedrock and Microsoft Azure. Claude Opus 4.6 is also available for Claude Chat, Claude Cowork and Claude Code
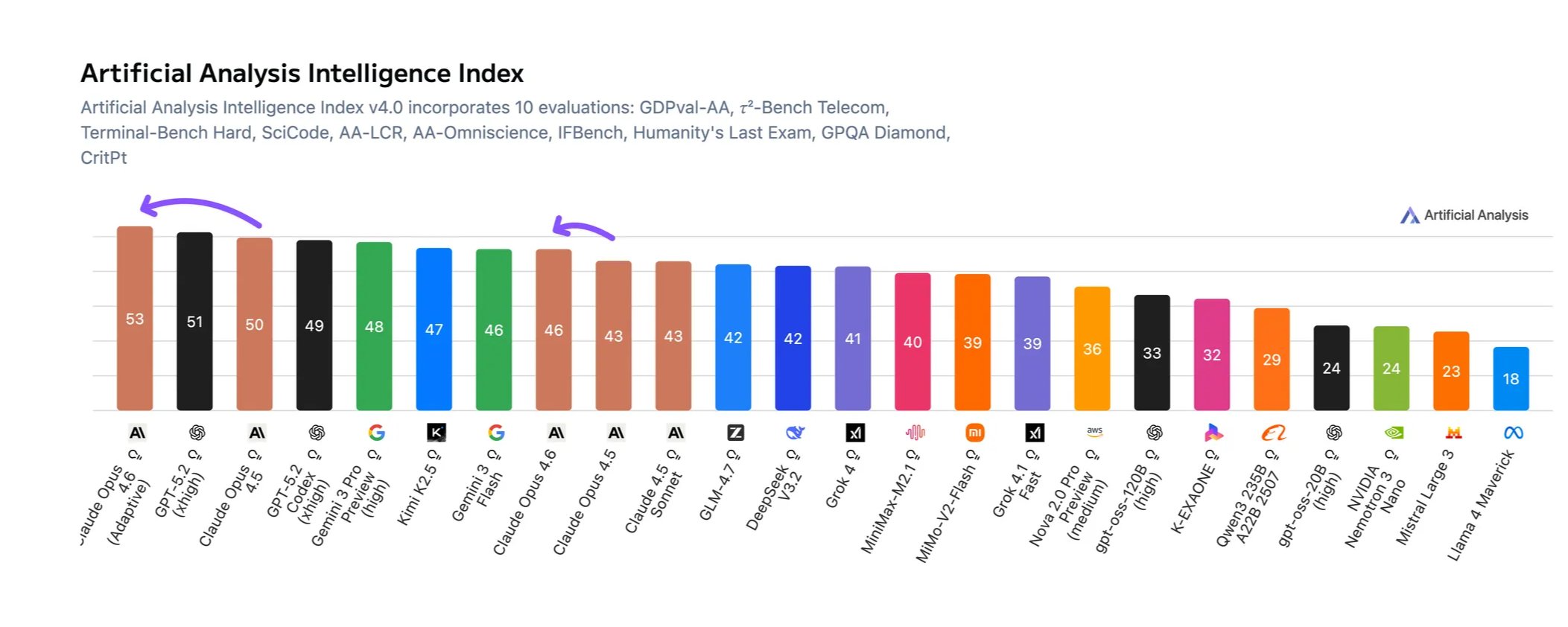 Claude Opus 4.6 takes first place in the Artificial Analysis Intelligence Index
Claude Opus 4.6 takes first place in the Artificial Analysis Intelligence Index
Opus 4.6 (Adaptive) is the second most expensive model to run the Artificial Analysis Intelligence Index, behind GPT-5.2 Codex (xhigh) - notably more expensive than GPT-5.2 (xhigh), the now second place model on the Intelligence Index. Anthropic has priced Opus 4.6 identically to Opus 4.5 at $5/$25 per million input/output tokens.
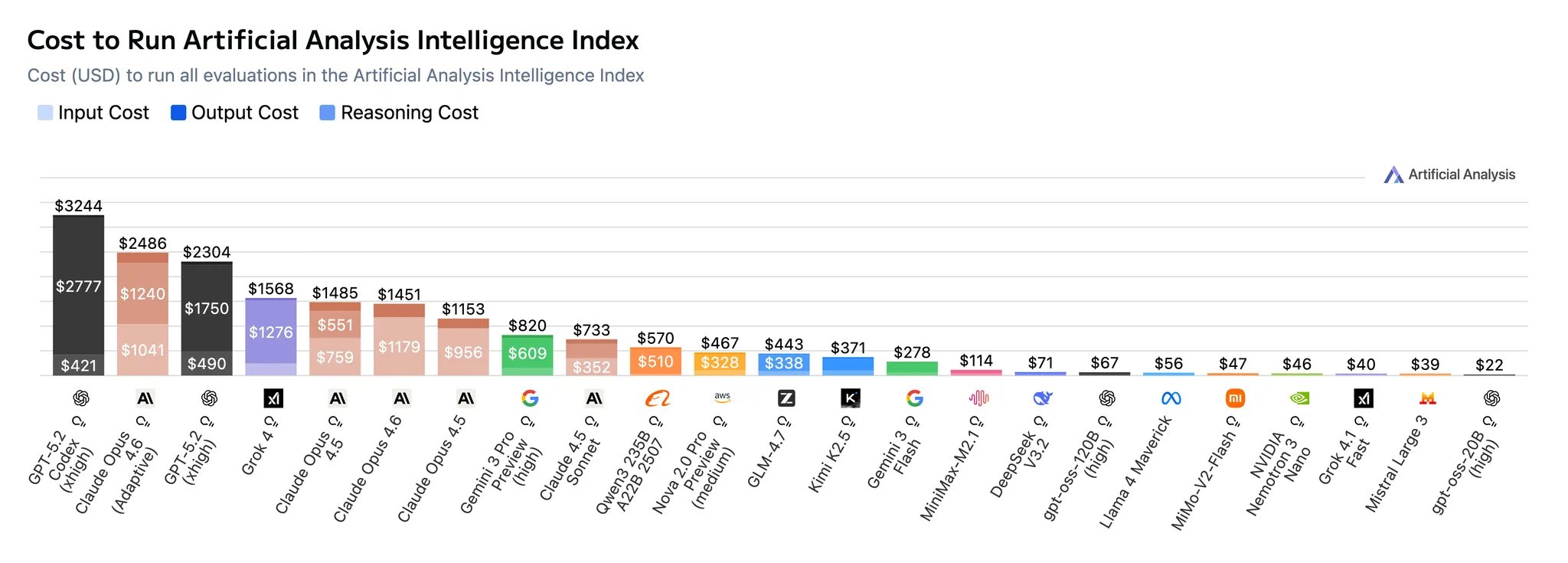 Opus 4.6 cost analysis compared to other frontier models
Opus 4.6 cost analysis compared to other frontier models
A key differentiator for the Claude models remains that they are more token-efficient than most other frontier models. Claude Opus 4.6 (Adaptive) uses ~2x the number of output tokens as Opus 4.5 (Thinking), but less than frontier peer models. Both configurations of Claude Opus 4.6 that we tested are on the Pareto frontier of the Intelligence vs. Output Tokens chart.
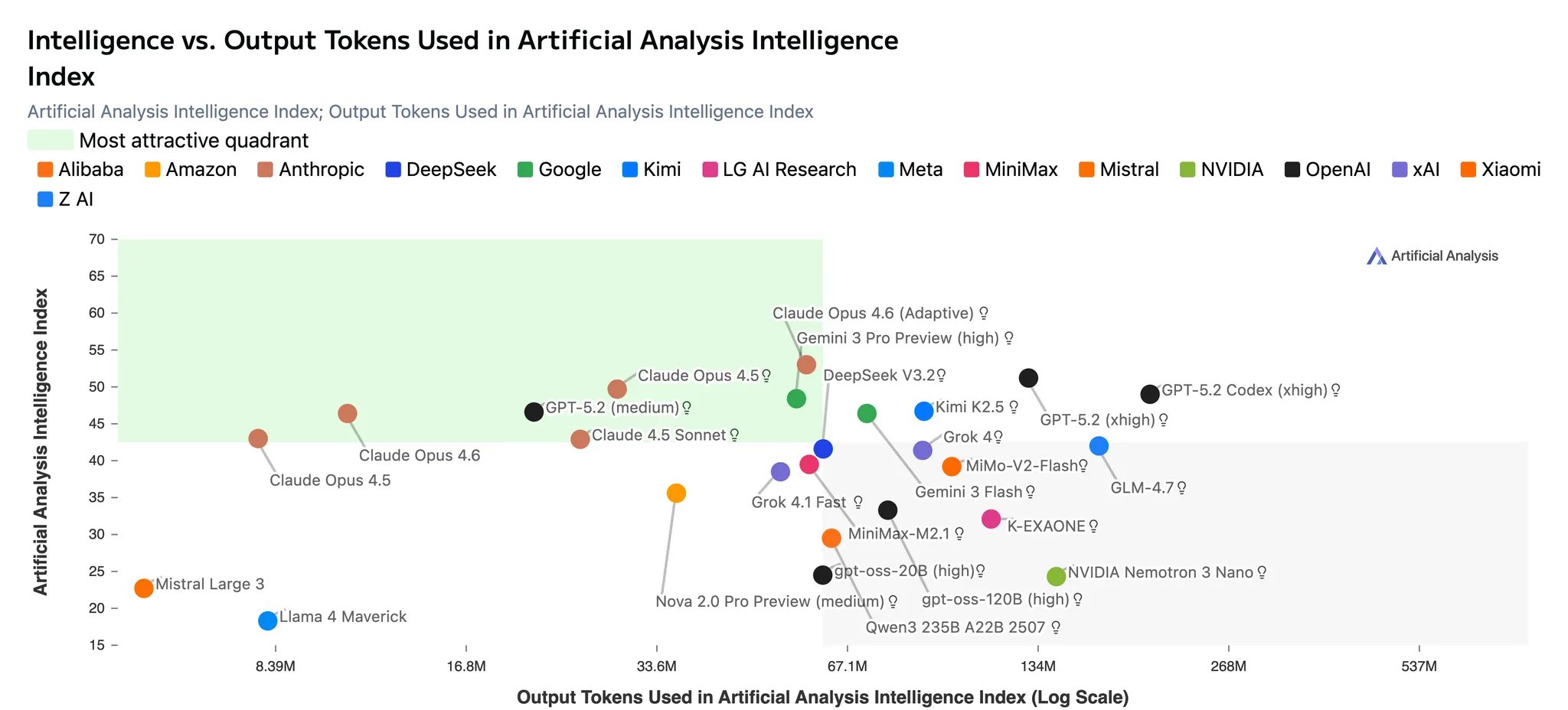 Intelligence vs Output Tokens showing Claude Opus 4.6 efficiency
Intelligence vs Output Tokens showing Claude Opus 4.6 efficiency
Opus 4.6 (Adaptive) achieves the highest score (13%) on CritPT, an evaluation consisting of unpublished research-level physics problems. Opus 4.6 also achieves a score of ~3% on CritPT in non-thinking mode, placing ahead of several frontier models that 'think' before they answer.
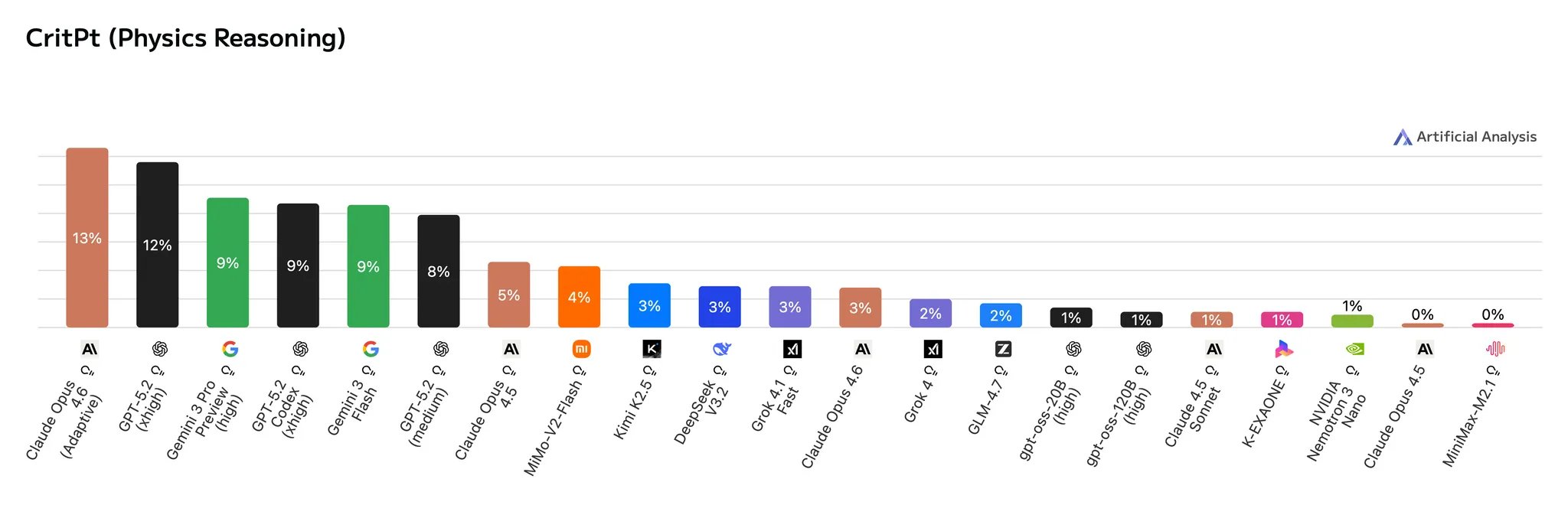 CritPT physics evaluation results showing Opus 4.6 leadership
CritPT physics evaluation results showing Opus 4.6 leadership
Opus 4.6 (Adaptive) takes the #2 spot on the Artificial Analysis Omniscience Index, our proprietary benchmark for measuring knowledge and hallucination across domains. The adaptive variant has the third highest accuracy and the fourth lowest hallucination rate, offering a better balance of higher accuracy and lower hallucination rate compared to peer models.
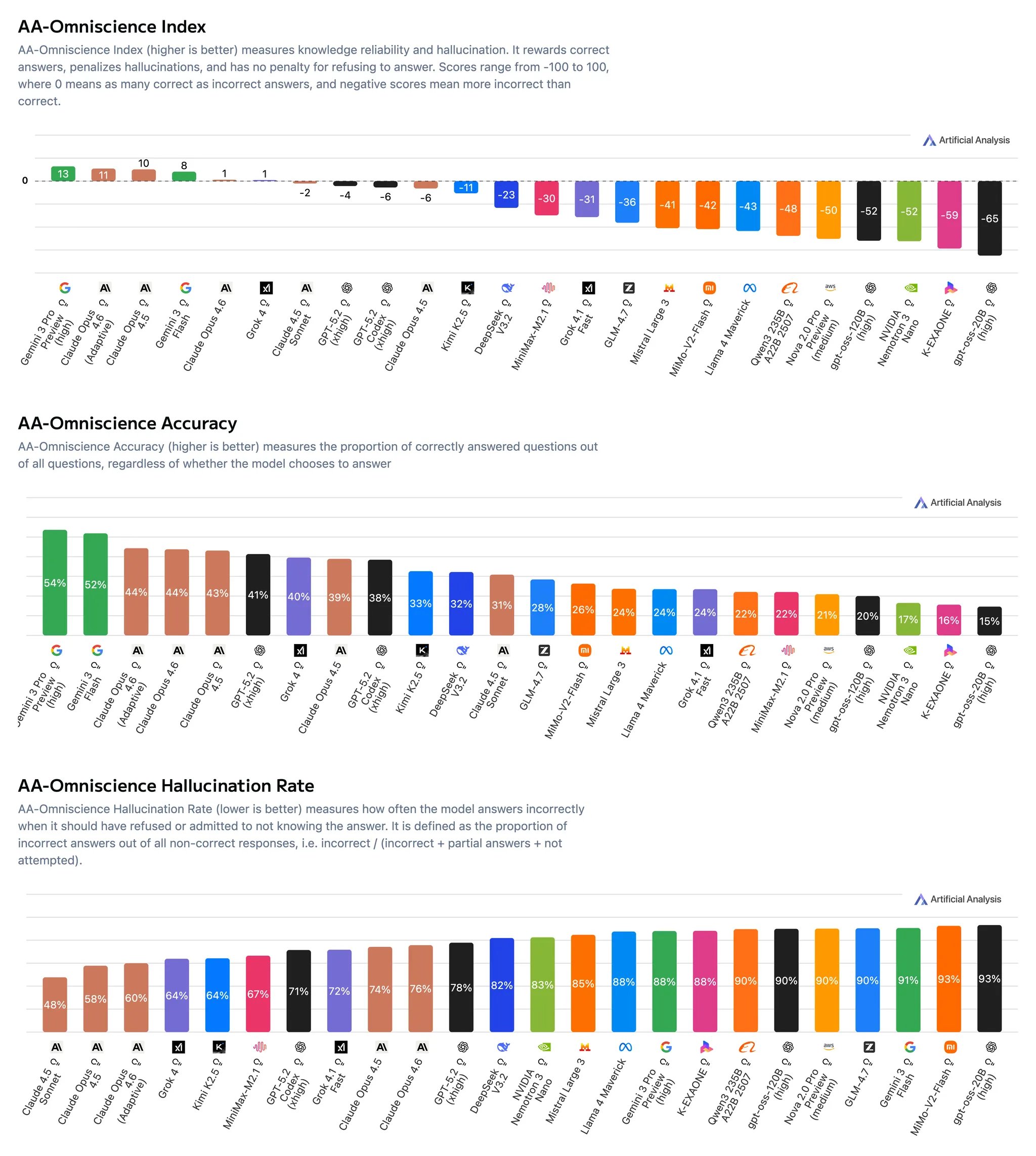 Artificial Analysis Omniscience Index results
Artificial Analysis Omniscience Index results
Opus 4.6 (Adaptive) leads GDPval-AA, our primary metric for general agentic performance, measuring the performance of models on knowledge work tasks from preparing presentations and data analysis through to video editing. Models use shell access and web browsing in an agentic loop through Stirrup, our open-source agentic reference harness.
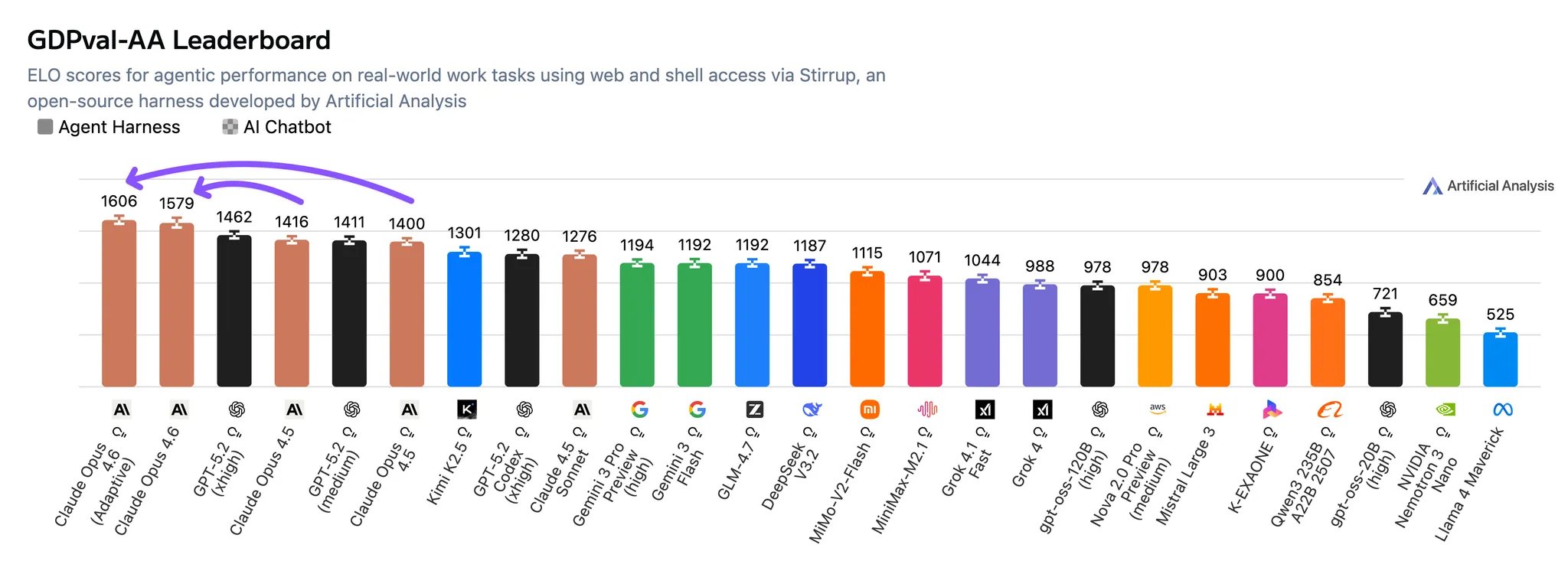 GDPval-AA agentic performance leaderboard
GDPval-AA agentic performance leaderboard
See Artificial Analysis for further details and benchmarks of Claude Opus 4.6: https://artificialanalysis.ai/
Want to dive deeper? Discuss this model with our Discord community: https://discord.gg/ATfzv9v9