January 28, 2026
Kimi K2.5: Everything You Need to Know
Moonshot’s Kimi K2.5 is the new leading open weights model, now closer than ever to the frontier - with only OpenAI, Anthropic and Google models ahead
Key takeaways:
➤ Impressive performance on agentic tasks: Kimi K2.5 achieves an Elo of 1309 on our GDPval-AA evaluation, behind only OpenAI and Anthropic models. Kimi K2.5 leaps ahead of GLM-4.7, DeepSeek V3.2 and Gemini 3 Pro. GDPval-AA is our leading metric for general agentic performance, measuring the performance of models on realistic knowledge work tasks such as preparing presentations and analysis. Models are given shell access and web browsing capabilities in an agentic loop via our reference agentic harness called Stirrup.
➤ Native multimodality for the first time: Kimi K2.5 is the first flagship model from Moonshot to support multimodal (image and video) inputs. This is the first time that the leading open weights model has supported image input, removing a critical barrier to the adoption of open weights models compared to proprietary models from the frontier labs. It represents significant differentiation for Kimi K2.5 compared to other open weights leaders including DeepSeek V3.2, GLM-4.7, MiniMax M2.1 and MiMo-V2-Flash. Kimi K2.5 scores 75% on the MMMU Pro visual reasoning benchmark, slightly behind Gemini 3 Pro but in line with GPT-5.2 and Claude Opus 4.5.
➤ Moderate cost to run Artificial Analysis Intelligence Index: Kimi K2.5 lands at $371 in Cost to Run Artificial Analysis Intelligence Index, more than 4x cheaper than Claude Opus 4.5 and GPT-5.2, but more than 5x more expensive than DeepSeek V3.2 and gpt-oss-120b.
➤ Moderate token usage: Kimi K2.5 demonstrates token usage comparable to other models in the same intelligence tier, using ~82M reasoning tokens across the Artificial Analysis Intelligence Index evaluation suite. This is slightly lower than Kimi K2 Thinking (~95M reasoning tokens) and much lower than GLM 4.7 (~160M reasoning tokens).
➤ Open weights: Kimi K2.5 is an MoE model with 1T total parameters and 32B active. Similar to Kimi K2 Thinking, Kimi K2.5 has been released in native INT4 precision rather than FP8/BF16. This means the model is only ~595GB.
➤ Hybrid reasoning: Kimi K2.5 unifies Moonshot’s reasoning and non-reasoning models into a single model. We have evaluated K2.5 with reasoning on (and will share results soon with reasoning off).
➤ Low hallucination rate: Kimi K2.5 scores -11 on the AA-Omniscience Index, our knowledge evaluation measuring both accuracy and hallucination rate. This score is primarily driven by a comparatively low hallucination rate of 64% (reduced from Kimi K2 Thinking's 74%), indicating a slightly greater tendency to abstain rather than fabricate knowledge when the model is uncertain.
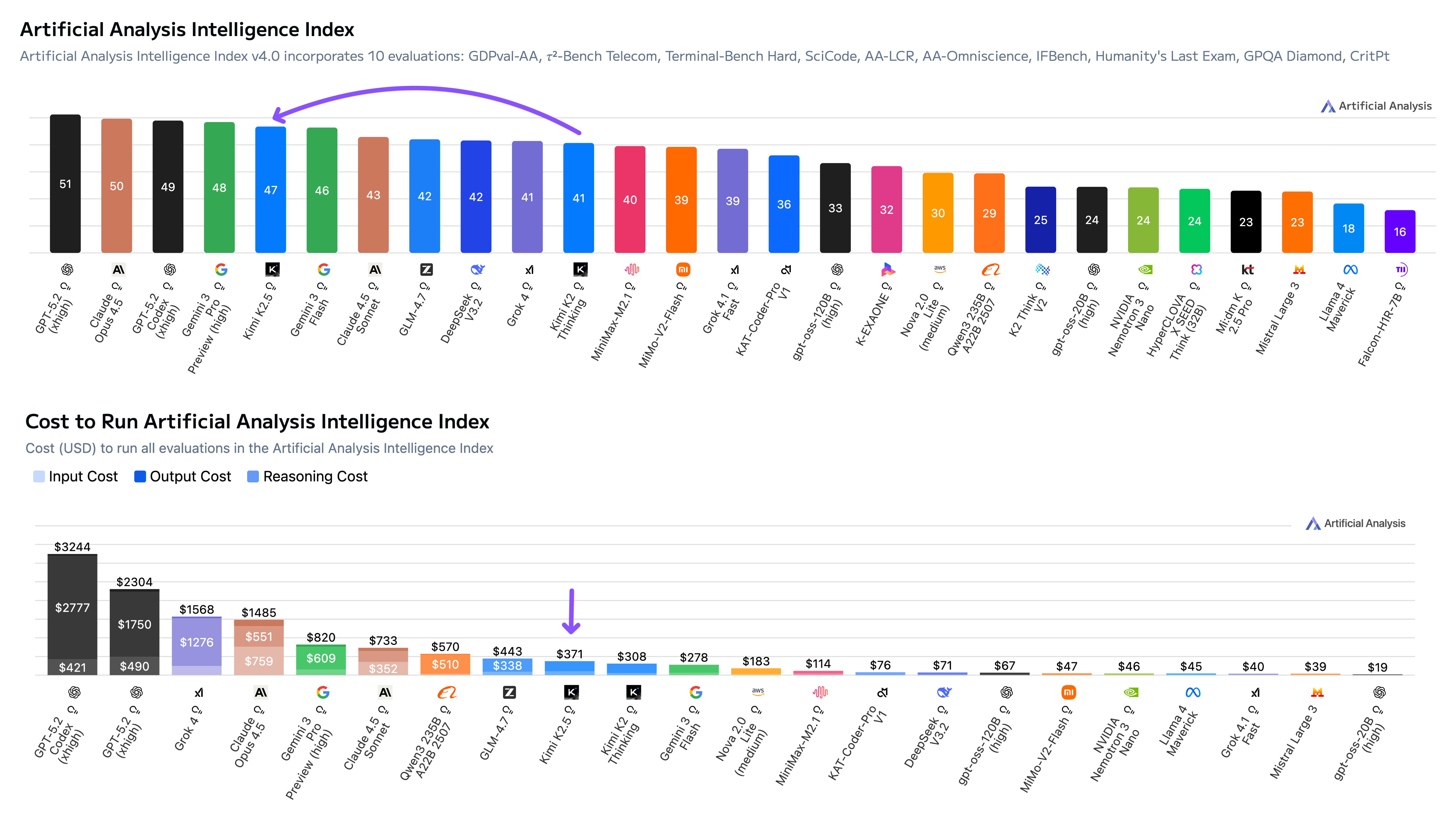 Artificial Analysis Intelligence Index
Artificial Analysis Intelligence Index
Kimi K2.5 debuts with an Elo score of 1309 on the GDPval-AA Leaderboard, implying a win rate of 66% against GLM-4.7, the prior open weights leader.
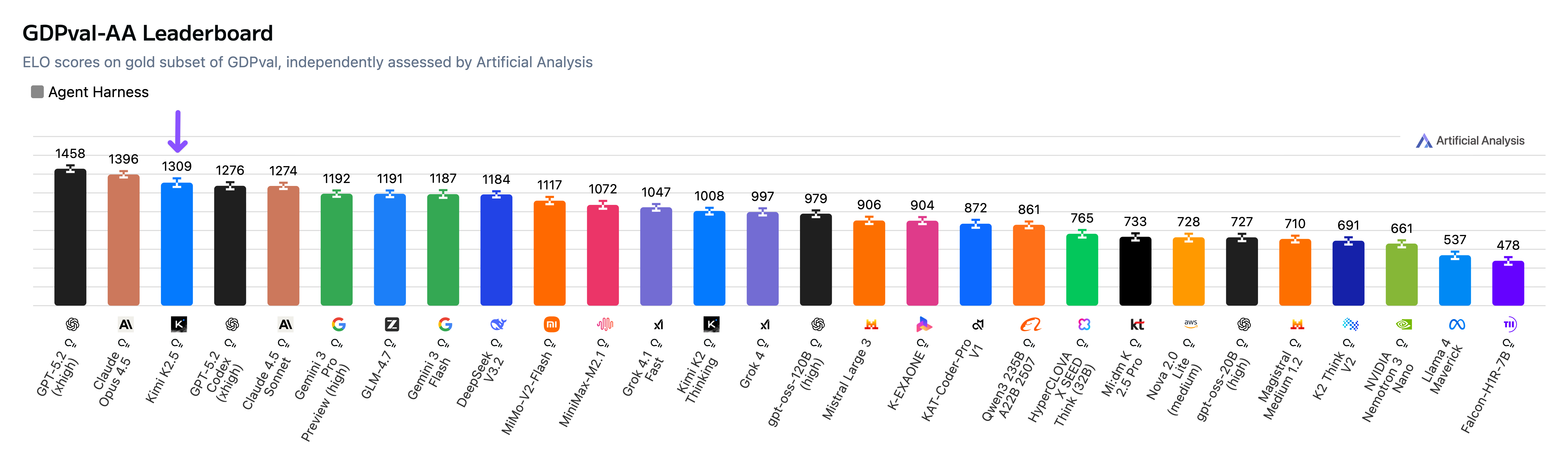 GDPval-AA Performance
GDPval-AA Performance
Kimi K2.5 costs $371 to run the Artificial Analysis Intelligence Index, making it more expensive than other open weights models but significantly cheaper than frontier proprietary models.
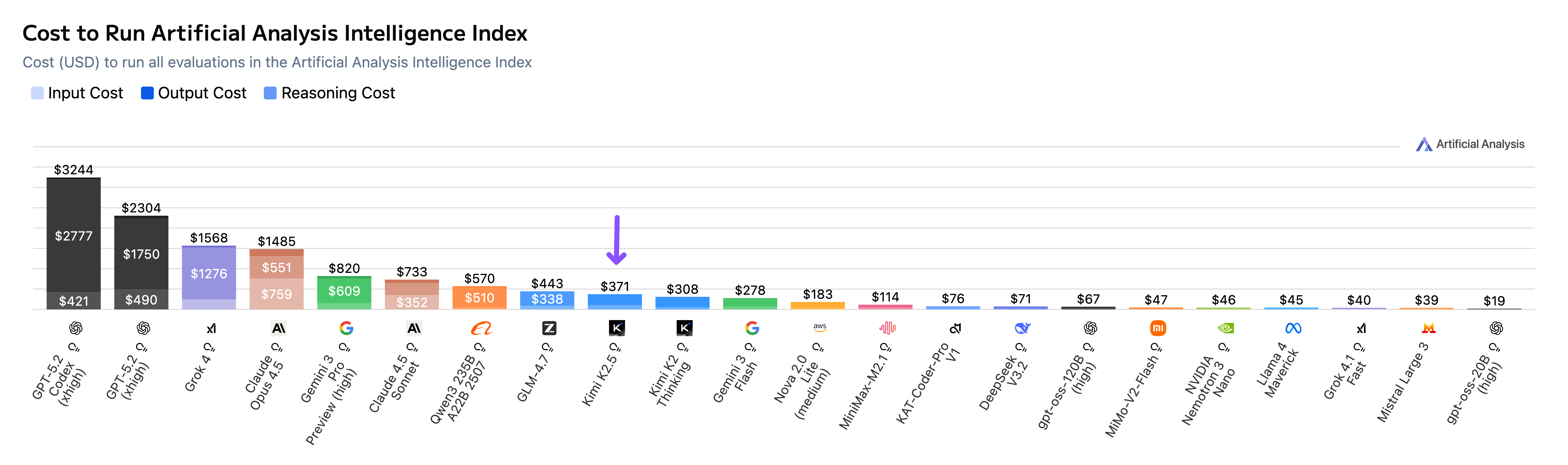 Cost to Run Analysis
Cost to Run Analysis
Kimi K2.5 is slightly less token intensive than Kimi K2 Thinking.
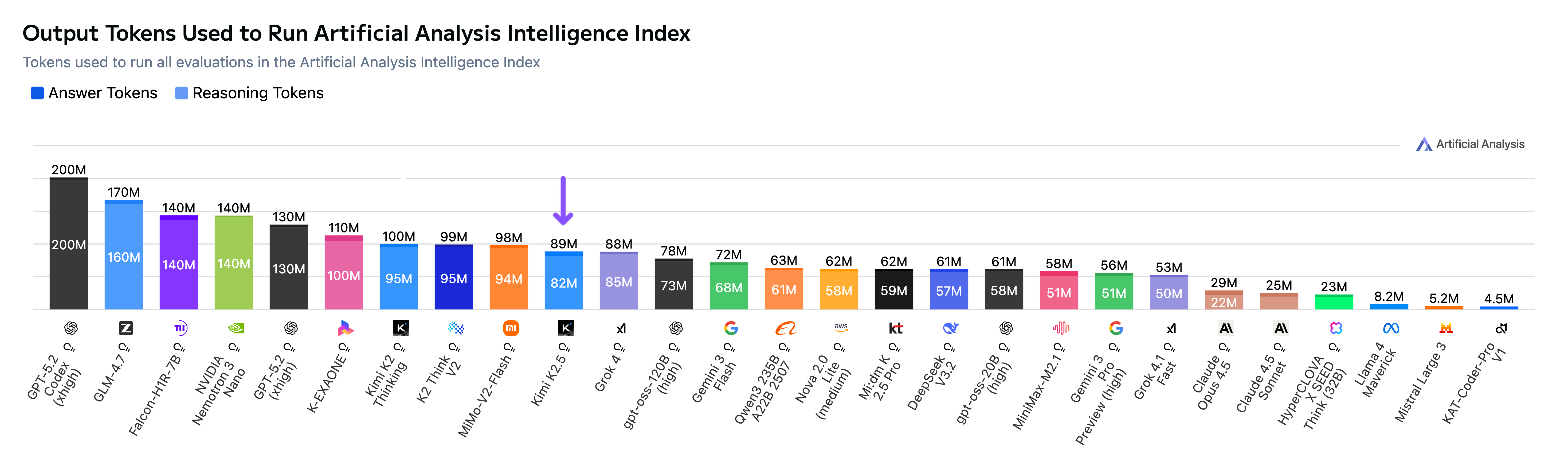 Output Tokens Usage
Output Tokens Usage
Kimi K2.5 scores -11 on the AA-Omniscience Index.
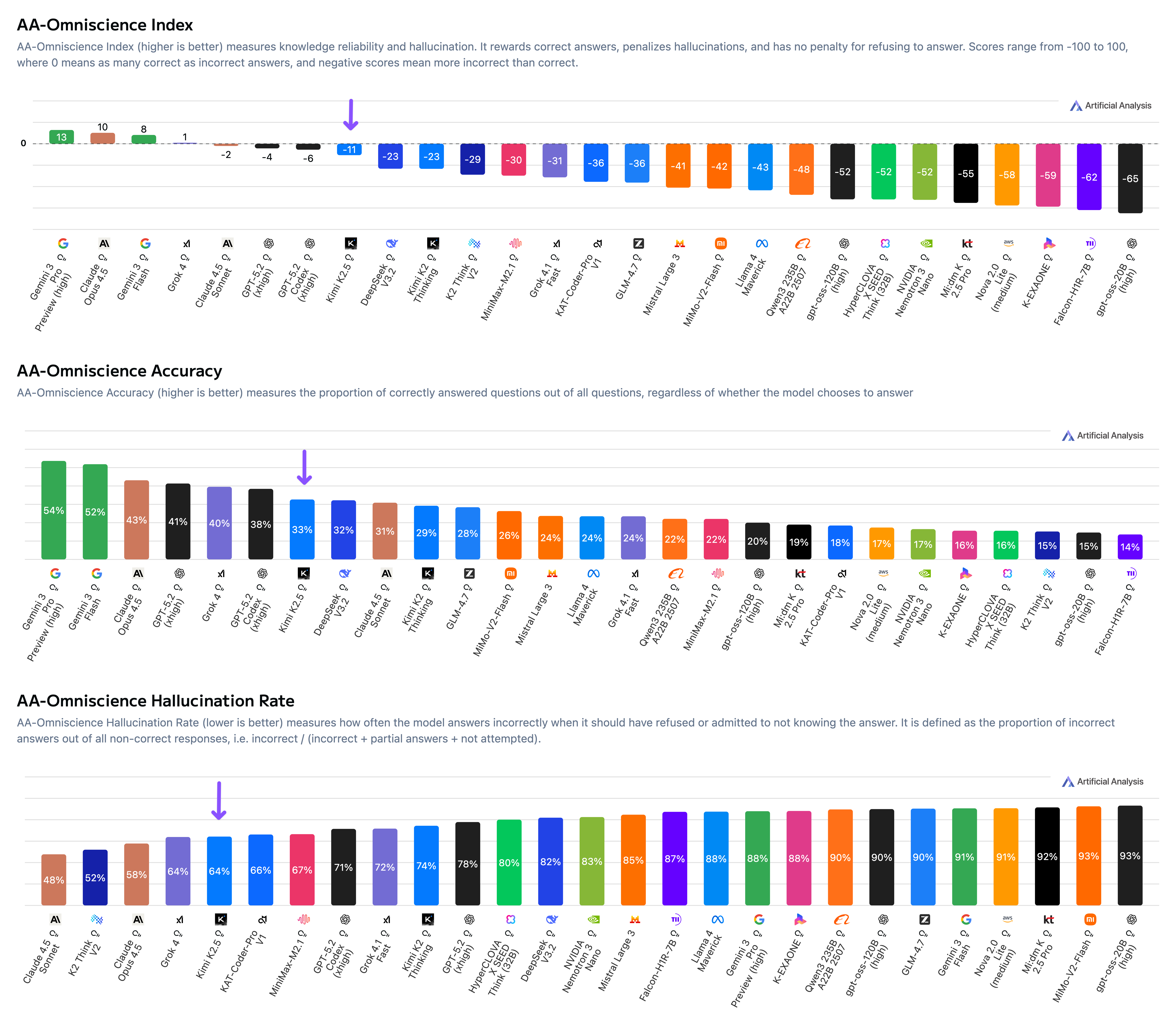 AA-Omniscience Index
AA-Omniscience Index
See Artificial Analysis for further details and benchmarks of Kimi K2.5: https://artificialanalysis.ai/
Want to dive deeper? Discuss this model with our Discord community: https://discord.gg/ATfzv9v9